Clase 12 Métodos basados en árboles
12.1 Árboles para regresión y clasificación.
La idea básica de los árboles es buscar puntos de cortes en las variables de entrada para hacer predicciones, ir dividiendo la muestra, y encontrar cortes sucesivos para refinar las predicciones.
Ejemplo
Buscamos clasificar hogares según su ingreso, usando como entradas características de los hogares. Podríamos tener, por ejemplo:
knitr::include_graphics('./figuras/arboles_1.png')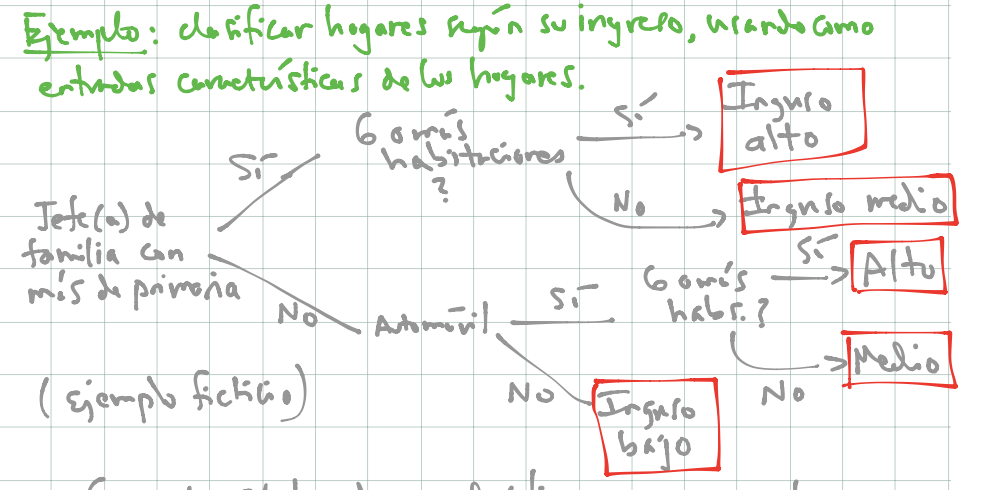
- Con este árbol podemos clasificar nuevos hogares.
- Nótese que los árboles pueden capturar interacciones entre las variables de entradas. En nuestro ejemplo ficticio, “automóvil” nos da información acerca del ingreso, pero solo caundo el nivel de educación del jefe de familia es bajo. (Ejercicio: si el ingreso fuera una cantidad numérica, ¿cómo escribirías este modelo con una suma de términos que involucren las variables mostradas en el diagrama?)
- Los árboles también pueden aproximar relaciones no lineales entre entradas y variable de salida (es similar a los ejemplos donde haciamos categorización de variables de entrada).
- Igual que en redes neuronales, en lugar de buscar puntos de corte o interacciones a mano, con los árboles intentamos encontrarlos de manera automática.
12.1.1 Árboles para clasificación
Un árbol particiona el espacio de entradas en rectángulos paralelos a los ejes, y hace predicciones basadas en un modelo simple dentro de cada una de esas particiones.
Por ejemplo:
knitr::include_graphics('./figuras/arboles_2.png')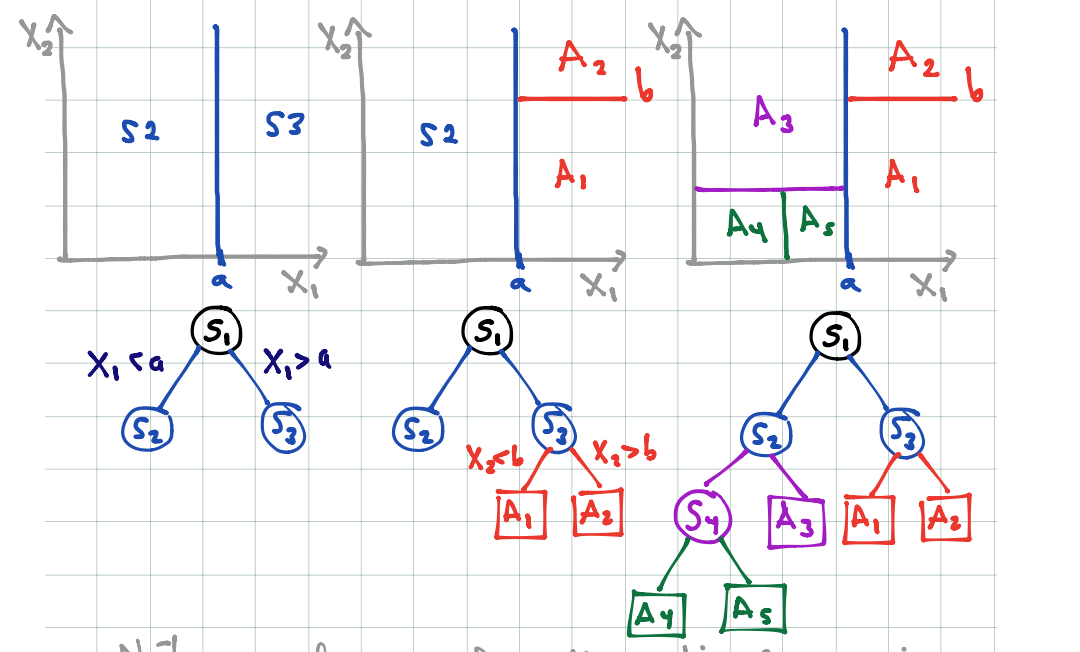
- El proceso de partición binaria recursiva (con una entrada a la vez) puede representarse mediante árboles binarios.
- Los nodos terminales representan a la partición obtenida.
Para definir el proceso de construcción de los árboles, debemos definir:
- ¿Cómo escoger las particiones? Idea: buscar hacer los nodos sucesivamente más puros (que una sola clase domine).
- ¿Cuándo declarar a un nodo como terminal? ¿Cuándo particionar más profundamente? Idea: dependiendo de la aplicación, buscamos hacer árboles chicos, o en otras árboles grandes que después podamos para no sobreajustar.
- ¿Cómo hacer predicciones en nodos terminales? Idea: escoger la clase más común en cada nodo terminal (la de máxima probabilidad).
12.1.2 Tipos de partición
Supongamos que tenemos variables de entrada \((X_1,\ldots, X_p)\). Recursivamente particionamos cada nodo escogiendo entre particiones tales que:
- Dependen de una sola variable de entrada \(X_i\)
- Si \(X_i\) es continua, la partición es de la forma \(\{X_i\leq c\},\{X_i> c\}\), para alguna \(c\) (punto de corte)
- Si \(X_i\) es categórica, la partición es de la forma \(\{X_i\in S\},\{X_i\notin S\}\), para algún subconjunto \(S\) de categorías de \(X_i\).
- En cada nodo candidato, escogemos uno de estos cortes para particionar.
¿Cómo escogemos la partición en cada nodo? En cada nodo, la partición se escoge de una manera miope o local, intentando separar las clases lo mejor que se pueda (sin considerar qué pasa en cortes hechos más adelante). En un nodo dado, escogemos la partición que reduce lo más posible su impureza.
12.1.3 Medidas de impureza
Consideramos un nodo \(t\) de un árbol \(T\), y sean \(p_1(t),\ldots, p_K(t)\) las proporciones de casos de \(t\) que caen en cada categoría.
12.1.3.1 Ejemplo
Graficamos la medida de impureza para dos clases:
impureza <- function(p){
-(p*log(p) + (1-p)*log(1-p))
}
curve(impureza, 0,1)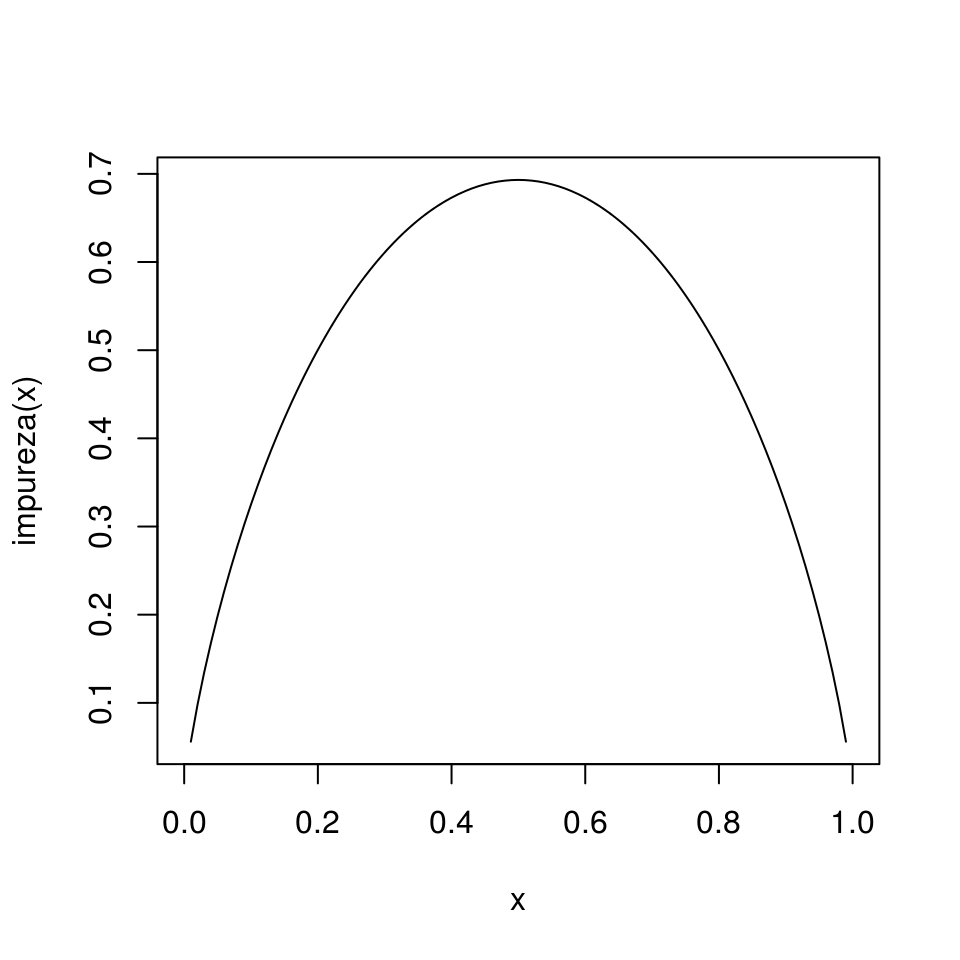
Donde vemos que la máxima impureza se alcanza cuando las proporciones de clase en un nodo son 50-50, y la mínima impureza (máxima pureza) se alcanza cuando en el nodo solo hay casos de una clase. Nótese que esta cantidad es proporcional a la devianza del nodo, donde tenemos porbabilidad constante de clase 1 igual a \(p\).
12.1.4 Reglas de partición y tamaño del árobl
Podemos escribir la regla de partición, que se aplica a cada nodo de un árbol
Ejemplo
Consideremos un nodo \(t\), cuyos casos de entrenamiento son:
n_t <- c(200,100, 150)
impureza <- function(p){
-sum(p*log(p))
}
impureza(n_t/sum(n_t))## [1] 1.060857Y comparamos con
n_t <- c(300,10, 140)
impureza <- function(p){
p <- p[p>0]
-sum(p*log(p))
}
impureza(n_t/sum(n_t))## [1] 0.7181575Ahora supongamos que tenemos un posible corte, el primero resulta en
n_t <- c(300,10, 140)
n_1 = c(300,0,0)
n_2 = c(0,10,140)
(sum(n_1)/sum(n_t))*impureza(n_1/sum(n_1)) + (sum(n_2)/sum(n_t))*impureza(n_2/sum(n_2))## [1] 0.08164334Un peor corte es:
n_t <- c(300,10, 140)
n_1 = c(200,0,40)
n_2 = c(100,10,100)
(sum(n_1)/sum(n_t))*impureza(n_1/sum(n_1)) + (sum(n_2)/sum(n_t))*impureza(n_2/sum(n_2))## [1] 0.6377053Lo que resta explicar es qué criterio de paro utilizamos para dejar de particionar.
Regla de paro Cuando usemos árboles en ótros métodos, generalmente hay dos opciones:
- Particionar hasta cierta profundidad fija (por ejemplo, máximo 8 nodos terminales). Este enfoque generalmente usa árboles relativamente chicos (se usa en boosting de árboles).
- Dejar de particionar cuando encontramos un número mínimo de casos en un nodo (por ejemplo, 5 o 10 casos). Este enfoque resulta en árboles grandes, probablemente sobreajustados (se usa en bosques aleatorios).
Y cuando utilizamos los árboles por sí solos para hacer predicciones:
- Podemos probar distintos valores de tamaño de árbol, y escogemos por validación (muestra o cruzada) el tamaño final.
- Podemos usar el método CART de Breiman, que consiste en construir un árbol grande y luego podar al tamaño correcto.
Ejemplo
Construímos algunos árboles con los datos de spam:
library(rpart)
library(rpart.plot)
library(ggplot2)
library(dplyr)
library(tidyr)
spam_entrena <- read.csv('./datos/spam-entrena.csv')
spam_prueba <- read.csv('./datos/spam-prueba.csv')
head(spam_entrena)## X wfmake wfaddress wfall wf3d wfour wfover wfremove wfinternet wforder
## 1 1 0.00 0.57 0.00 0 0.00 0 0 0 0.00
## 2 2 1.24 0.41 1.24 0 0.00 0 0 0 0.00
## 3 3 0.00 0.00 0.00 0 0.00 0 0 0 0.00
## 4 4 0.00 0.00 0.48 0 0.96 0 0 0 0.48
## 5 5 0.54 0.00 0.54 0 1.63 0 0 0 0.00
## 6 6 0.00 0.00 0.00 0 0.00 0 0 0 0.00
## wfmail wfreceive wfwill wfpeople wfreport wfaddresses wffree wfbusiness
## 1 0 0.57 0.57 1.15 0 0 0.00 0.00
## 2 0 0.00 0.41 0.00 0 0 0.41 0.00
## 3 0 0.00 0.00 0.00 0 0 0.00 0.00
## 4 0 0.00 0.00 0.00 0 0 0.96 0.96
## 5 0 0.00 0.54 0.00 0 0 0.54 0.54
## 6 0 0.00 0.00 0.00 0 0 0.00 0.00
## wfemail wfyou wfcredit wfyour wffont wf000 wfmoney wfhp wfhpl wfgeorge
## 1 1.73 3.46 0 1.15 0 0.00 0.00 0 0 0.0
## 2 0.82 3.73 0 1.24 0 0.00 0.41 0 0 0.0
## 3 0.00 12.19 0 4.87 0 0.00 9.75 0 0 0.0
## 4 0.00 1.44 0 0.48 0 0.96 0.00 0 0 0.0
## 5 0.00 2.17 0 5.97 0 0.54 0.00 0 0 0.0
## 6 0.00 5.00 0 0.00 0 0.00 0.00 0 0 2.5
## wf650 wflab wflabs wftelnet wf857 wfdata wf415 wf85 wftechnology wf1999
## 1 0 0 0 0 0 0 0 0 0 0
## 2 0 0 0 0 0 0 0 0 0 0
## 3 0 0 0 0 0 0 0 0 0 0
## 4 0 0 0 0 0 0 0 0 0 0
## 5 0 0 0 0 0 0 0 0 0 0
## 6 0 0 0 0 0 0 0 0 0 0
## wfparts wfpm wfdirect wfcs wfmeeting wforiginal wfproject wfre wfedu
## 1 0 0 0 0 0 0 0 0.00 0
## 2 0 0 0 0 0 0 0 0.41 0
## 3 0 0 0 0 0 0 0 0.00 0
## 4 0 0 0 0 0 0 0 0.48 0
## 5 0 0 0 0 0 0 0 0.00 0
## 6 0 0 0 0 0 0 0 0.00 0
## wftable wfconference cfsc cfpar cfbrack cfexc cfdollar cfpound
## 1 0 0 0 0.000 0.000 0.107 0.000 0.000
## 2 0 0 0 0.065 0.000 0.461 0.527 0.000
## 3 0 0 0 0.000 0.000 0.000 0.000 0.000
## 4 0 0 0 0.133 0.066 0.468 0.267 0.000
## 5 0 0 0 0.000 0.000 0.715 0.318 0.000
## 6 0 0 0 0.000 0.000 0.833 0.000 0.416
## crlaverage crllongest crltotal spam
## 1 1.421 7 54 1
## 2 3.166 19 114 1
## 3 1.000 1 7 0
## 4 3.315 61 242 1
## 5 2.345 22 129 1
## 6 1.937 8 31 0Podemos construir un árbol grande. En este caso, buscamos que los nodos resultantes tengan al menos un caso y para particionar pedimos que el nodo tenga al menos 10 casos:
set.seed(22)
control_completo <- rpart.control(cp=0,
minsplit=10,
minbucket=1,
xval=10,
maxdepth=30)
spam_tree_completo<-rpart(spam ~ ., data = spam_entrena, method = "class",
control = control_completo)
prp(spam_tree_completo, type=4, extra=4)## Warning: labs do not fit even at cex 0.15, there may be some overplotting
Podemos examinar la parte de arriba del árbol:
arbol.chico.1 <- prune(spam_tree_completo, cp=0.07)
prp(arbol.chico.1, type = 4, extra = 4)
Podemos hacer predicciones con este árbol grande. Por ejemplo, en entrenamiento tenemos:
prop <- predict(spam_tree_completo, newdata = spam_entrena)
table(prop[,2]>0.5, spam_entrena$spam )##
## 0 1
## FALSE 1835 34
## TRUE 26 1172y en prueba:
prop_arbol_grande <- predict(spam_tree_completo, newdata = spam_prueba)
tab_confusion <- table(prop_arbol_grande[,2]>0.5, spam_prueba$spam )
prop.table(tab_confusion, 2)##
## 0 1
## FALSE 0.90507012 0.11202636
## TRUE 0.09492988 0.88797364Y notamos la brecha grande entre prueba y entrenamiento, lo que sugiere sobreajuste. Este árbol es demasiado grande.
12.1.5 Costo - Complejidad (Breiman)
Una manera de escoger árboles del tamaño correcto es utilizando una medida inventada por Breiman para medir la calidad de un árbol. La complejidad de un árbol \(T\) está dada por (para \(\alpha\) fija):
\[C_\alpha (T) = \overline{err}(T) + \alpha \vert T\vert\] donde
- \(\overline{err}(T)\) es el error de clasificación de \(T\)
- \(\vert T\vert\) es el número de nodos terminales del árbol
- \(\alpha>0\) es un parámetro de penalización del tamaño del árbol.
Esta medida de complejidad incluye qué tan bien clasifica el árbol en la muestra de entrenamiento, pero penaliza por el tamaño del árbol.
Para escoger el tamaño del árbol correcto, definimos \(T_\alpha \subset T\) como el subárbol de \(T\) que minimiza la medida \(C_\alpha (T_\alpha)\).
Para entender esta decisión, obsérvese que:
- Un subárbol grande de \(T\) tiene menor valor de \(\overline{err}(T)\) (pues usa más cortes)
- Pero un subárbol grande de \(T\) tiene más penalización por complejidad \(\alpha\vert T\vert\).
De modo que para \(\alpha\) fija, el árbol \(T_\alpha\) hace un balance entre error de entrenamiento y penalización por complejidad.
12.1.5.1 Ejemplo
Podemos ver subárboles más chicos creados durante el procedimiento de división de nodos (prp está el paquete rpart.plot). En este caso pondemos \(\alpha = 0.2\) (cp = \(\alpha\) = complexity parameter):
arbol.chico.1 <- prune(spam_tree_completo, cp=0.2)
prp(arbol.chico.1, type = 4, extra = 4)
Si disminuimos el coeficiente \(\alpha\).
arbol.chico.1 <- prune(spam_tree_completo, cp=0.07)
prp(arbol.chico.1, type = 4, extra = 4)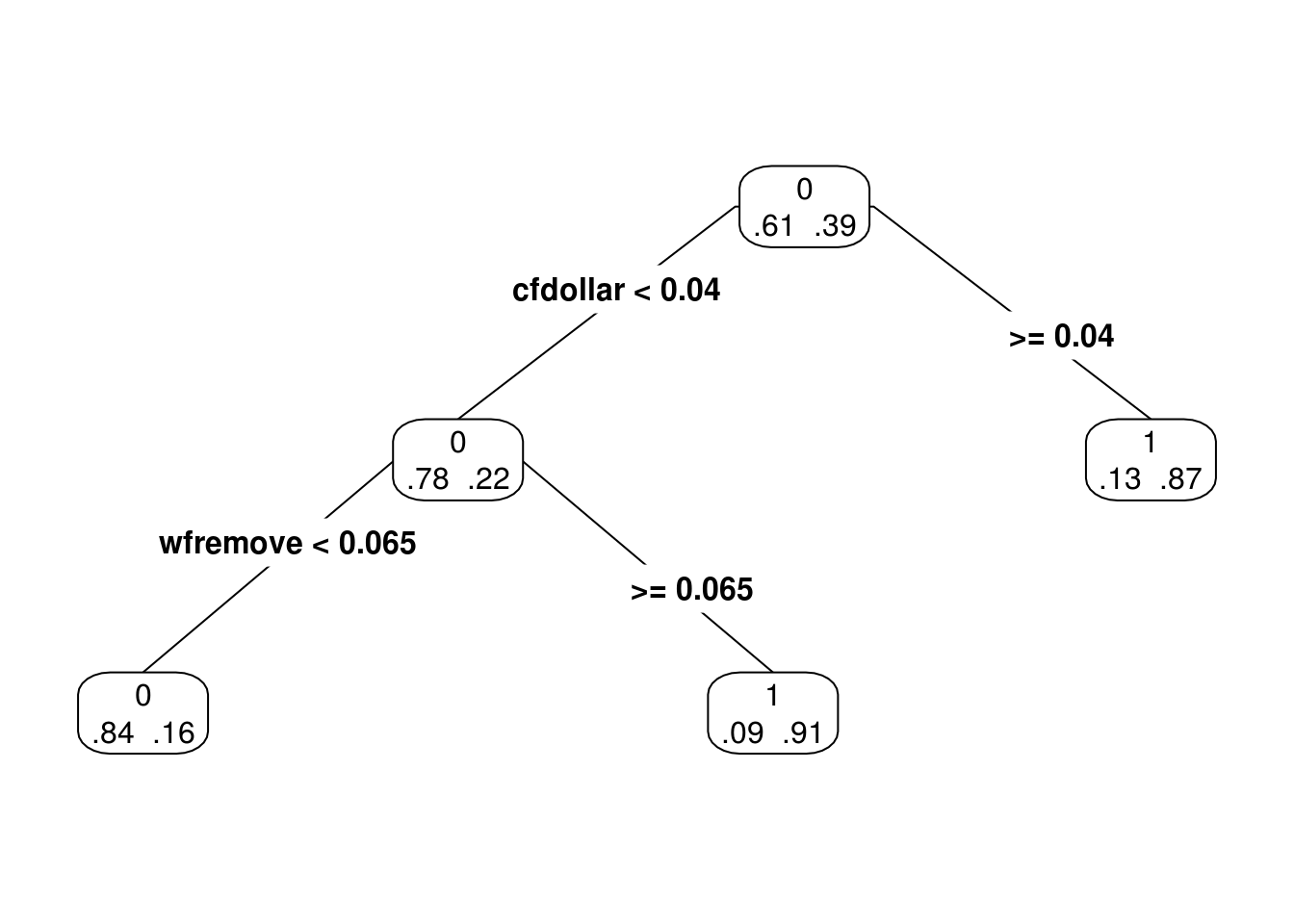
y vemos que en efecto el árbol \(T_{0.07}\) contiene al árbol \(T_{0.2}\), y ambos son subárboles del árbol gigante que construimos al principio.
Nota: Esto es un teorema que hace falta demostrar: el resultado principal es que conforme aumentamos \(\alpha\), vamos eliminiando ramas del árbol, de manera que los
arbol.chico.1 <- prune(spam_tree_completo, cp=0.05)
prp(arbol.chico.1, type = 4, extra = 4)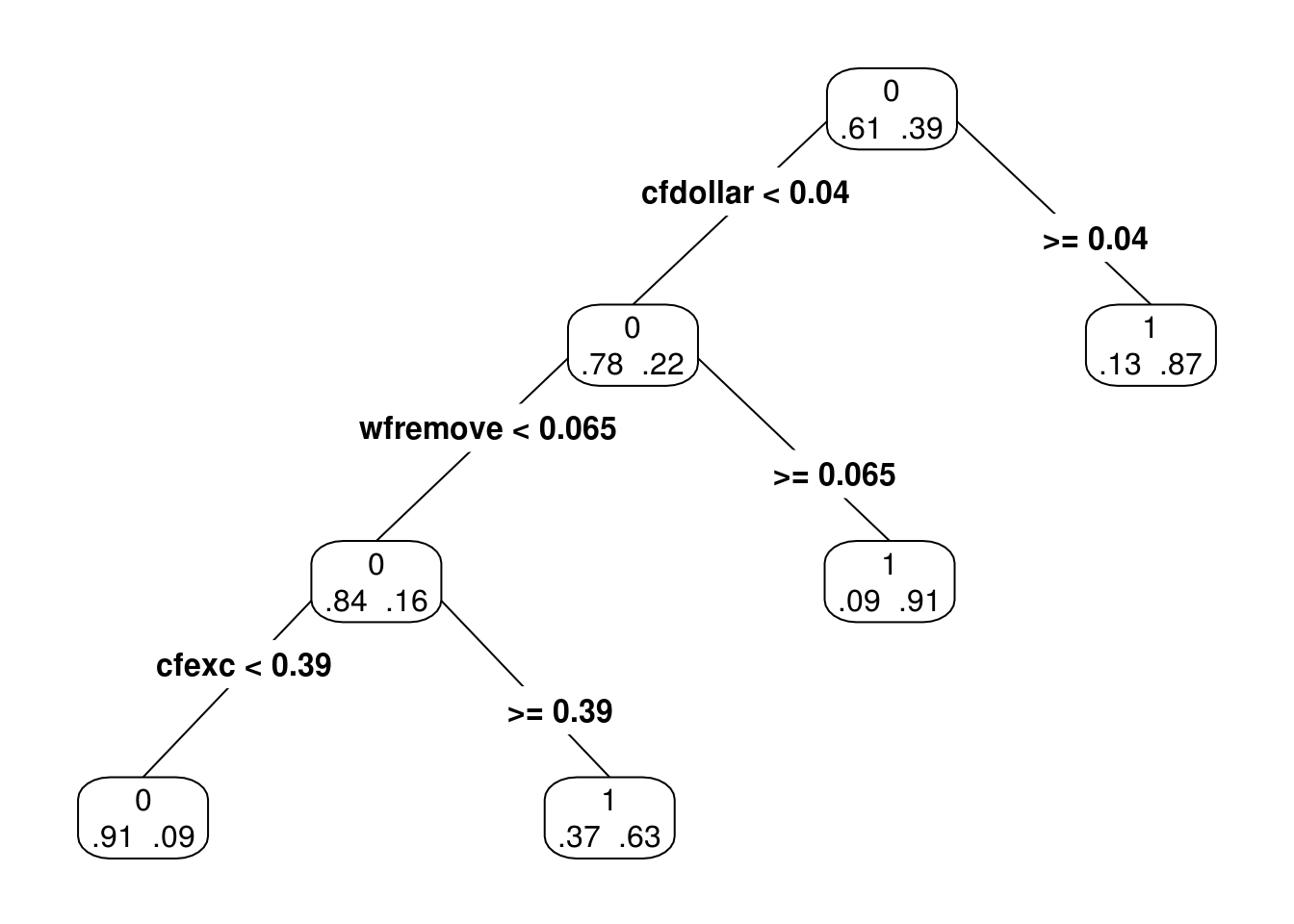
arbol.chico.1 <- prune(spam_tree_completo, cp=0.02)
prp(arbol.chico.1, type = 4, extra = 4)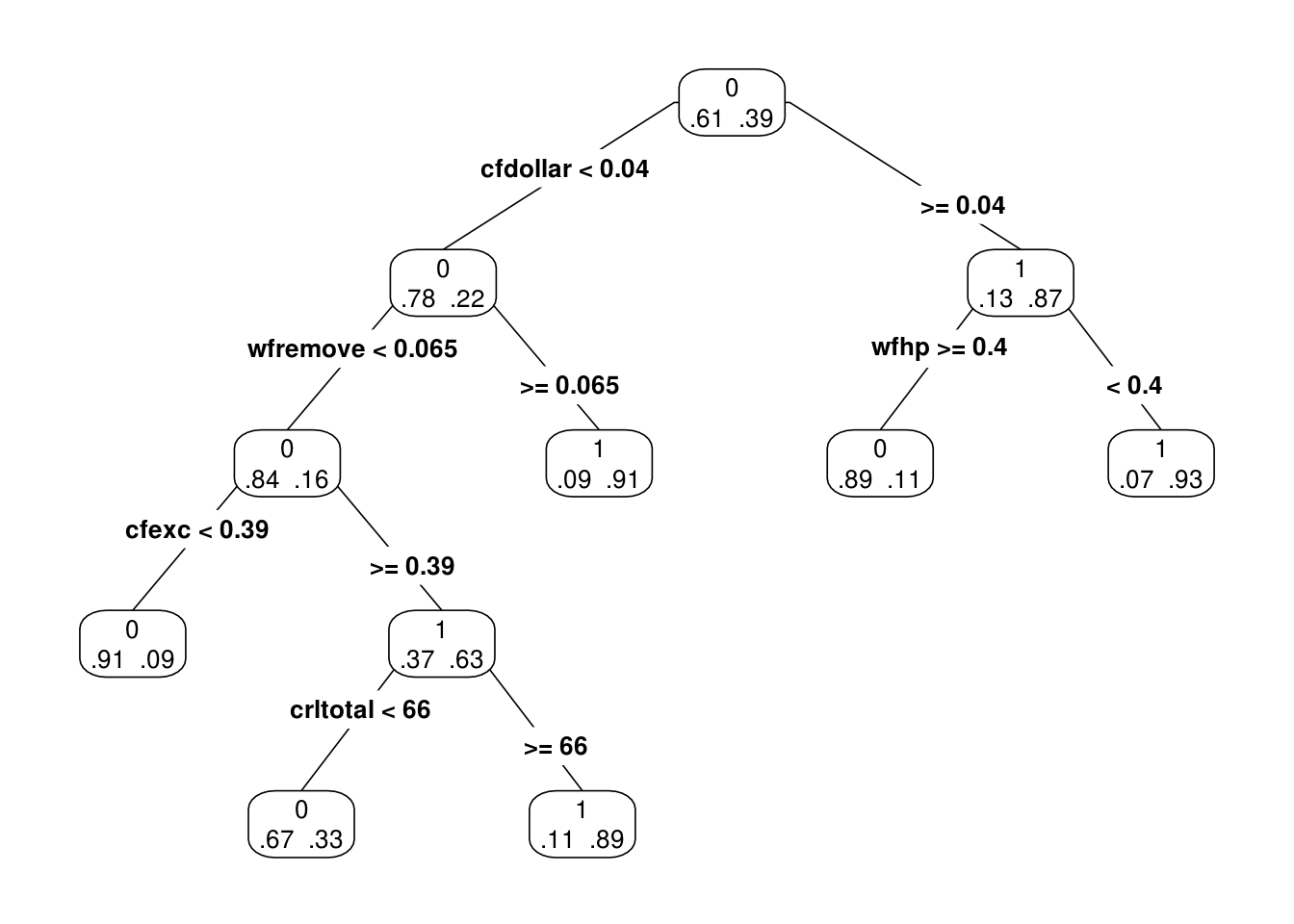
source('./scripts/fancyRpartPlot.R')
fancyRpartPlot(arbol.chico.1, sub='')## Loading required package: RColorBrewer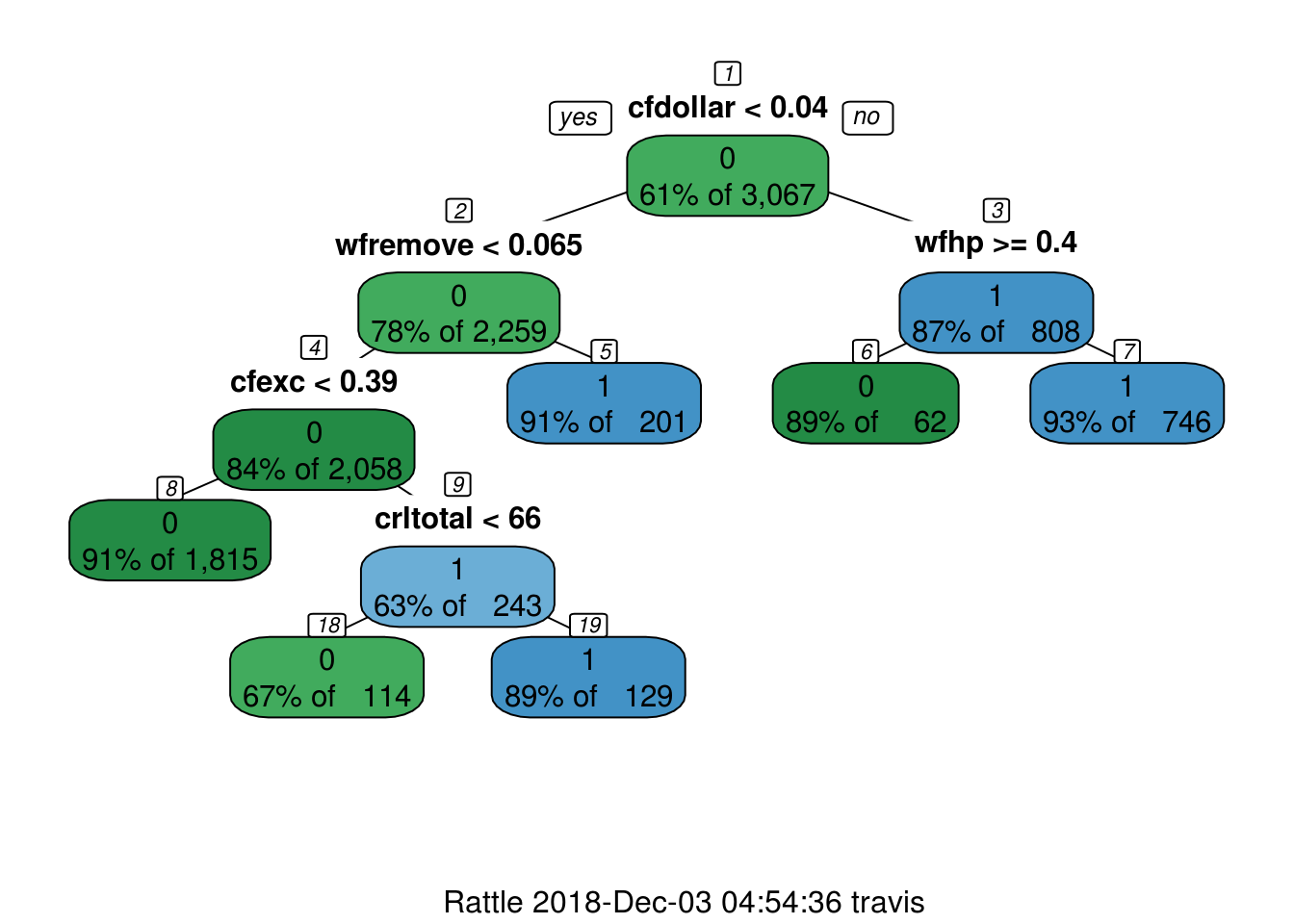
Nota: Enfoques de predicción basados en un solo árbol para clasificación y regresión son típicamente superados en predicción por otros métodos. ¿Cuál crees que sea la razón? ¿Es un problema de varianza o sesgo?
12.1.6 (Opcional) Predicciones con CART
Podemos hacer predicciones con un sólo árbol. En el caso de spam, haríamos
set.seed(9293) # para hacer reproducible la validación cruzada
spam_tree <-rpart(spam ~ ., data = spam_entrena,
method = "class", control=list(cp=0,
minsplit=5,minbucket=1))Ahora mostramos los resultados de cada árbol para cada valor de \(\alpha\). La siguiente función nos da una estimación de validación cruzada del error:
printcp(spam_tree)##
## Classification tree:
## rpart(formula = spam ~ ., data = spam_entrena, method = "class",
## control = list(cp = 0, minsplit = 5, minbucket = 1))
##
## Variables actually used in tree construction:
## [1] cfbrack cfdollar cfexc cfpar cfsc
## [6] crlaverage crllongest crltotal wf1999 wf3d
## [11] wf650 wfaddress wfall wfbusiness wfconference
## [16] wfcredit wfdata wfdirect wfedu wfemail
## [21] wffont wffree wfgeorge wfhp wfhpl
## [26] wfinternet wflabs wfmail wfmake wfmeeting
## [31] wfmoney wforder wforiginal wfour wfover
## [36] wfpeople wfpm wfproject wfre wfreceive
## [41] wfremove wfreport wftechnology wfwill wfyou
## [46] wfyour X
##
## Root node error: 1206/3067 = 0.39322
##
## n= 3067
##
## CP nsplit rel error xerror xstd
## 1 0.49087894 0 1.000000 1.00000 0.022431
## 2 0.13681592 1 0.509121 0.54975 0.018903
## 3 0.05223881 2 0.372305 0.44942 0.017516
## 4 0.03980100 3 0.320066 0.34163 0.015659
## 5 0.03150912 4 0.280265 0.30514 0.014922
## 6 0.01160862 5 0.248756 0.28275 0.014436
## 7 0.01077944 6 0.237148 0.27612 0.014286
## 8 0.00663350 7 0.226368 0.25954 0.013901
## 9 0.00497512 9 0.213101 0.24046 0.013436
## 10 0.00414594 18 0.166667 0.21227 0.012701
## 11 0.00331675 20 0.158375 0.21144 0.012679
## 12 0.00276396 24 0.145108 0.20481 0.012496
## 13 0.00248756 27 0.136816 0.19320 0.012167
## 14 0.00165837 31 0.126036 0.18740 0.011997
## 15 0.00130301 44 0.104478 0.18408 0.011899
## 16 0.00124378 52 0.092869 0.18657 0.011973
## 17 0.00118455 54 0.090381 0.18740 0.011997
## 18 0.00110558 61 0.082090 0.18740 0.011997
## 19 0.00082919 67 0.075456 0.18823 0.012022
## 20 0.00066335 100 0.048093 0.19569 0.012238
## 21 0.00041459 107 0.043118 0.19652 0.012262
## 22 0.00033167 121 0.037313 0.20896 0.012611
## 23 0.00031095 126 0.035655 0.21144 0.012679
## 24 0.00027640 140 0.029851 0.21393 0.012746
## 25 0.00020730 146 0.028192 0.21393 0.012746
## 26 0.00010365 150 0.027363 0.21725 0.012836
## 27 0.00000000 158 0.026534 0.21725 0.012836Y usamos la regla de mínimo error o a una desviación estándar del error mínimo:
arbol_podado <- prune(spam_tree, cp = 0.00130301)
prp(arbol_podado)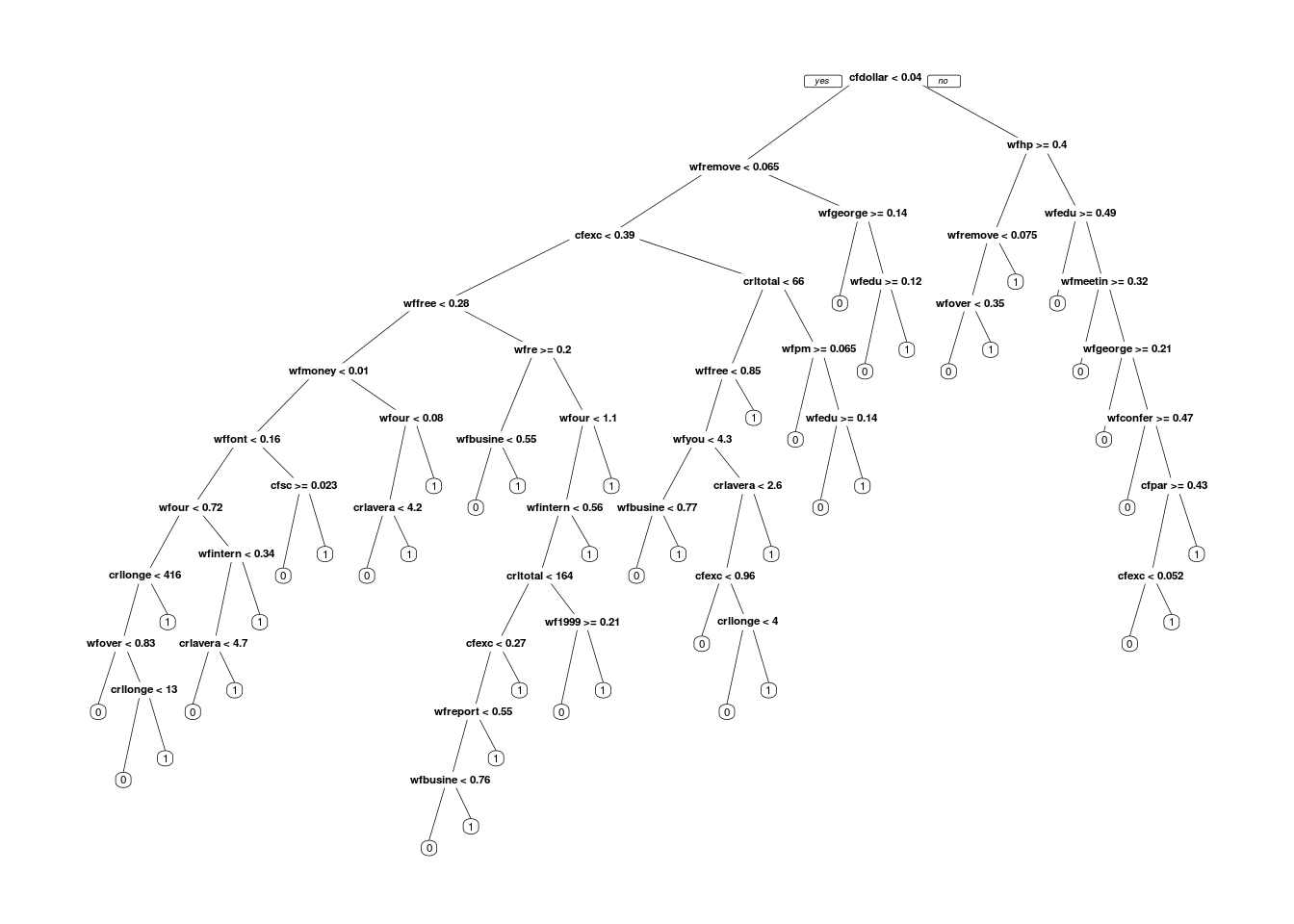
Cuyo error de predicción es:
prop_arbol_podado <- predict(arbol_podado, newdata=spam_prueba)
head(prop_arbol_podado)## 0 1
## 1 0.02578797 0.974212
## 2 0.02578797 0.974212
## 3 0.03703704 0.962963
## 4 0.12500000 0.875000
## 5 0.02578797 0.974212
## 6 0.02578797 0.974212prop.table(table((prop_arbol_podado[,2]>0.5),spam_prueba$spam),2)##
## 0 1
## FALSE 0.94282632 0.12191104
## TRUE 0.05717368 0.8780889612.1.7 Árboles para regresión
Para problemas de regresión, el criterio de pureza y la predicción en cada nodo terminal es diferente:
- En los nodos terminales usamos el promedio los casos de entrenamiento que caen en tal nodo (en lugar de la clase más común)
- La impureza de define como varianza: si \(t\) es un nodo, su impureza está dada por \(\frac{1}{n(t)}\sum (y - m)^2\), donde la suma es sobre los casos que están en el nodo y \(m\) es la media de las \(y\)’s del nodo.
12.1.8 Variabilidad en el proceso de construcción
Existe variabilidad considerable en el proceso de división, lo cual es una debilidad de los árboles. Por ejemplo:
set.seed(9923)
muestra.1 <- spam_entrena[sample(1:nrow(spam_entrena), nrow(spam_entrena), replace=T), ]
spam.tree.completo.1 <-rpart(spam ~ ., data = muestra.1, method = "class",
control = control_completo)
arbol.chico.1 <- prune(spam.tree.completo.1, cp=0.03)
prp(arbol.chico.1, type = 4, extra = 4)
muestra.1 <- spam_entrena[sample(1:nrow(spam_entrena), nrow(spam_entrena), replace=T), ]
spam.tree.completo.1 <-rpart(spam ~ ., data = muestra.1, method = "class",
control = control_completo)
arbol.chico.1 <- prune(spam.tree.completo.1, cp=0.03)
prp(arbol.chico.1, type = 4, extra = 4)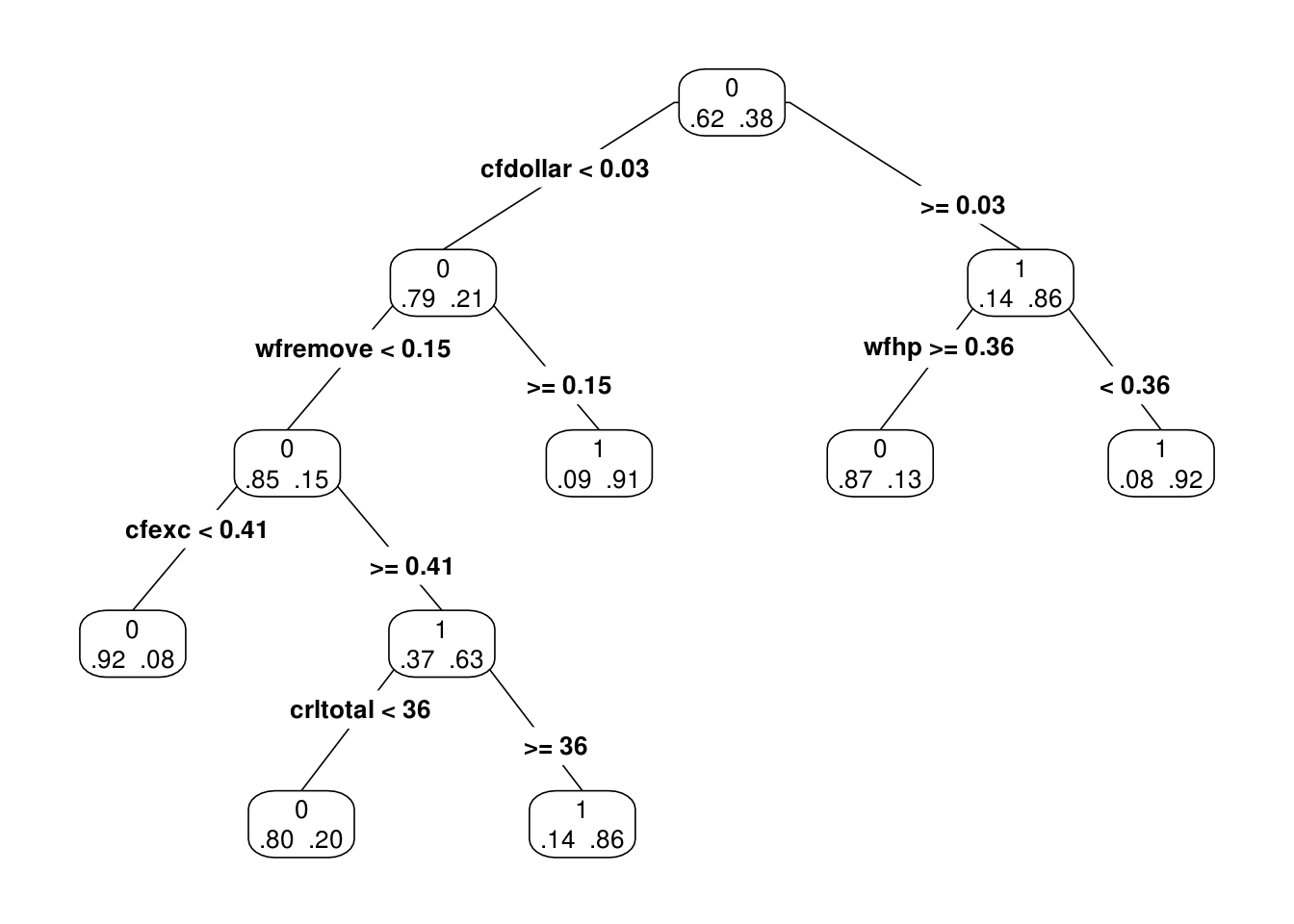
Pequeñas diferencias en la muestra de entrenamiento produce distintas selecciones de variables y puntos de corte, y estructuras de árboles muchas veces distintas. Esto introduce varianza considerable en las predicciones.
12.1.9 Relaciones lineales
Los árboles pueden requerir ser muy grandes para estimar apropiadamente relaciones lineales.
x <- runif(200,0,1)
y <- 2*x + rnorm(200,0,0.1)
arbol <- rpart(y~x, data=data_frame(x=x, y=y), method = 'anova')
x_pred <- seq(0,1,0.05)
y_pred <- predict(arbol, newdata = data_frame(x=x_pred))
y_verdadera <- 2*x_pred
dat <- data_frame(x_pred=x_pred, y_pred=y_pred, y_verdadera=y_verdadera) %>% gather(y, valor, y_pred:y_verdadera)
ggplot(dat, aes(x=x_pred, y=valor, colour=y)) + geom_line()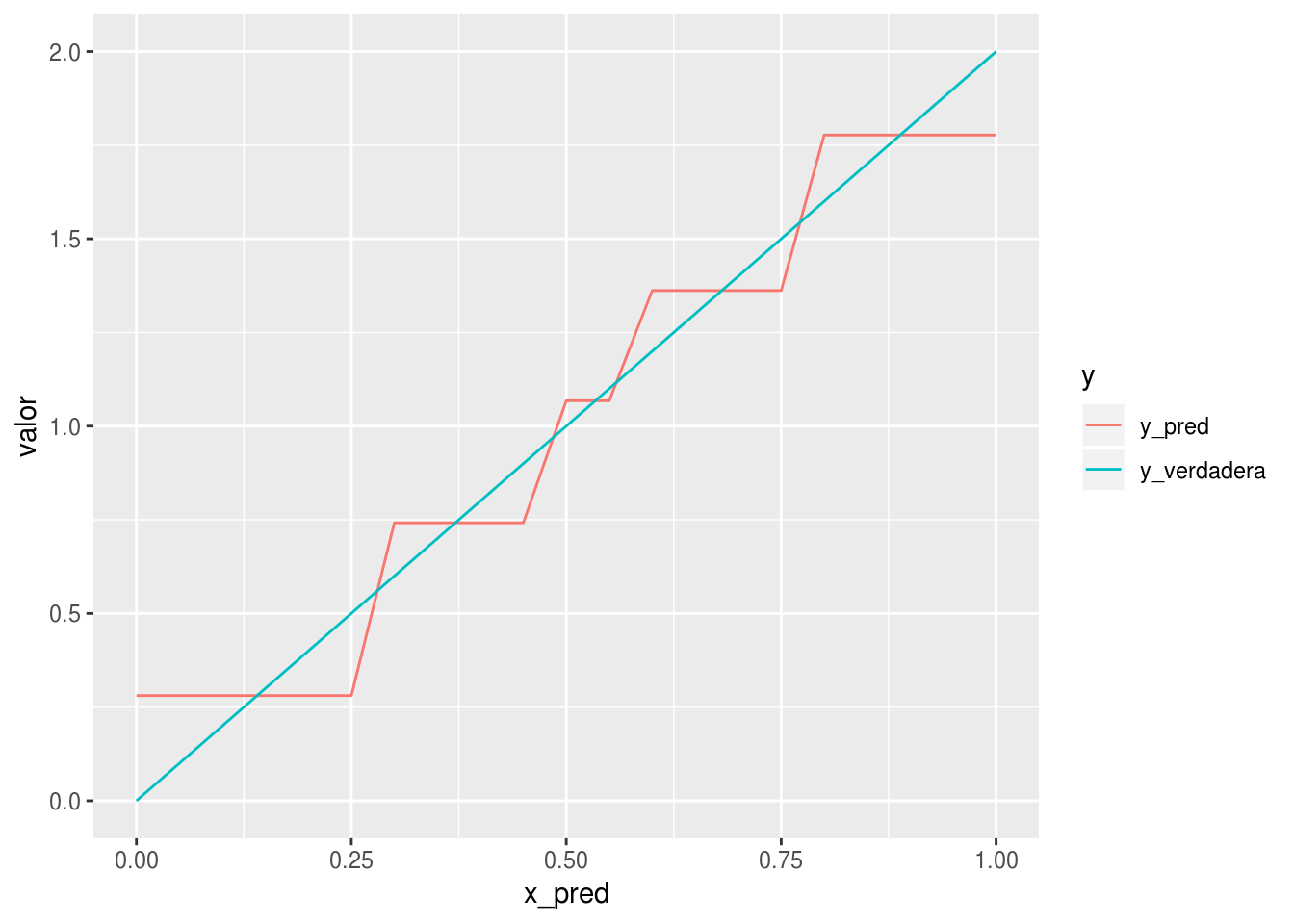
12.1.10 Ventajas y desventajas de árboles
Ventajas:
- Árboles chicos son relativamente fáciles de explicar
- Capturan interacciones entre las variables de entrada
- Son robustos en el sentido de que
- valores numéricos atípicos no hacen fallar al método
- no es necesario transformar (monótonamente) variables de entrada
- hay formas fáciles de lidiar con datos faltantes (cortes sucedáneos)
- Se ajustan rápidamente y son relativamente fáciles de interpretar (por ejemplo, son útiles para clasificar en campo)
- Árboles grandes generalmente no sufren de sesgo.
Desventajas:
- Tienen dificultades en capturar estructuras lineales.
- En la interpretación, tienen la dificultad de que muchas veces algunas variables de entrada “enmascaran” a otras. Que una variable de entrada no esté en el árbol no quiere decir que no sea “importante” para predecir (regresión ridge lidia mejor con esto).
- Son inestables (varianza alta) por construcción: es local/miope, basada en cortes duros si/no. Esto produce desempeño predictivo relativamente malo. (p ej: una pequeña diferencia en cortes iniciales puede resultar en estructuras de árbol totalmente distintas).
- Adicoinalmente, no son apropiados cuando hay variables categóricas con muchas niveles: en estos casos, el árbol sobreajusta desde los primeros cortes, y las predicciones son malas.
12.2 Bagging de árboles
Bosques aleatorios es un método de predicción que utiliza familias de árboles para hacer predicciones.
Los árboles grandes tienen la ventaja de tener sesgo bajo, pero sufren de varianza alta. Podemos explotar el sesgo bajo si logramos controlar la varianza. Una idea primera para lograr esto es es hacer bagging de árboles:
- Perturbar la muestra de entrenamiento de distintas maneras y producir árboles distintos (grandes). La perturbación más usada es tomar muestras bootstrap de los datos y ajustar un árbol a cada muestra bootstrap
- Promediar el resultado de todos estos árboles para hacer predicciones. El proceso de promediar reduce la varianza, sin tener pérdidas en sesgo.
La idea básica de bagging (bootstrap aggregation) es la siguiente:
Consideramos el proceso \({\mathcal L} \to T_{\mathcal L}\), que representa el proceso de ajuste de un árbol \(T_{\mathcal L}\) a partir de la muestra de entrenamiento \({\mathcal L}\). Si pudiéramos obtener distintas muestras de entrenamiento \[{\mathcal L}_1, {\mathcal L}_2, \ldots, {\mathcal L}_B,\] y supongamos que construimos los árboles (que suponemos de regresión) \[T_1, T_2, \ldots, T_B,\] Podríamos mejorar nuestras predicciones construyendo el árbol promedio \[T(x) = \frac{1}{B}\sum_{i=b}^B T_b (x)\] ¿Por qué es mejor este árbol promedio que cualquiera de sus componentes? Veamos primero el sesgo. El valor esperado del árbol promedio es \[E[T(x)] = \frac{1}{B}\sum_{i=b}^B E[T_b (x)]\] y como cada \(T_b(x)\) se construye de la misma manera a partir de \({\mathcal L}_b\), y todas las muestras \({\mathcal L}_b\) se extraen de la misma forma, todos los términos de la suma de la derecha son iguales: \[E[T(x)] = E[T_1 (x)],\] lo que implica que el sesgo del promedio es igual al sesgo de un solo árbol (que es bajo, pues suponemos que los árboles son grandes).
Ahora veamos la varianza. Como las muestras \({\mathcal L}_b\) se extraen de manera independiente, entonces
\[Var[T(x)] = Var\left( \frac{1}{B}\sum_{i=b}^B T_b (x)\right) = \frac{1}{B^2}\sum_{i=b}^B Var[T_b (x)],\] pues los distintos \(T_b(x)\) no están correlacionados (en ese caso, varianza de la suma es la suma de las varianzas), y las constantes salen de la varianza al cuadrado. Por las mismas razones que arriba, todos los términos de la derecha son iguales, y \[Var[T(x)] = \frac{1}{B}\ Var[T_1 (x)]\] de modo que la varianza del árbol promedio es mucho más chica que la varianza de un árbol dado (si \(B\) es grande).
Sin embargo, no podemos tomar muestras de entrenamiento repetidamente para ajustar estos árboles. ¿Cómo podemos simular extraer distintas muestras de entrenamiento?
Sabemos que si tenemos una muestra de entrenamiento fija \({\mathcal L}\), podemos evaluar la variación de esta muestra tomando muestras bootstrap de \({\mathcal L}\), que denotamos por
\[{\mathcal L}_1^*, {\mathcal L}_2^*, \ldots, {\mathcal L}_B^*,\]
Recordatorio: una muestra bootstrap de \(\mathcal L\) es una muestra con con reemplazo de \({\mathcal L}\) del mismo tamaño que \({\mathcal L}\).Entonces la idea es que construimos los árboles (que suponemos de regresión) \[T_1^*, T_2^*, \ldots, T_B^*,\] podríamos mejorar nuestras predicciones construyendo el árbol promedio \[T^*(x) = \frac{1}{B}\sum_{i=b}^B T_b^* (x)\] para suavizar la variación de cada árbol individual.
El argumento del sesgo aplica en este caso, pero el de la varianza no exactamente, pues las muestras bootstrap no son independientes (están correlacionadas a través de la muestra de entrenamiento de donde se obtuvieron),a pesar de que las muestras bootstrap se extraen de manera independiente de \({\mathcal L}\). De esta forma, no esperamos una reducción de varianza tan grande como en el caso de muestras independientes.
Bagging Sea \({\mathcal L} =\{(x^{(i)}, y^{(i)})\}_{i=1}^n\) una muestra de entrenamiento, y sean \[{\mathcal L}_1^*, {\mathcal L}_2^*, \ldots, {\mathcal L}_B^*,\] muestras bootstrap de \({\mathcal L}\) (muestreamos con reemplazo los pares \((x^{(i)}, y^{(i)})\), para obtener una muestra de tamaño \(n\)).
- Para cada muestra bootstrap construimos un árbol \[{\mathcal L}_b^* \to T_b^*\].
- (Regresión) Promediamos árboles para reducir varianza \[T^*(x) = \frac{1}{B}\sum_{i=b}^B T_b^*(x)\]
- (Clasificación) Tomamos votos sobre todos los árboles: \[T^*(x) = argmax_g \{ \# \{i|T_b^*(x)=g\}\}.\] Podemos también calcular probabilidades promedio sobre todos los árboles.
Nota: No hay garantía de bagging reduzca el error de entrenamiento, especialmente si los árboles base son muy malos clasificadores ¿Puedes pensar en un ejemplo donde empeora?
12.2.1 Ejemplo
Probemos con el ejemplo de spam. Construimos árboles con muestras bootstrap de los datos originales de entrenamiento:
muestra_bootstrap <- function(df){
df %>% sample_n(nrow(df), replace = TRUE)
}
arboles_bagged <- lapply(1:30, function(i){
muestra <- muestra_bootstrap(spam_entrena)
arbol <- rpart(spam ~ ., data = muestra,
method = "class", control=list(cp=0,
minsplit=5,minbucket=1))
arbol
})Examinemos la parte de arriba de algunos de estos árboles:
prp(prune(arboles_bagged[[1]], cp =0.01))## Warning: Cannot retrieve the data used to build the model (so cannot determine roundint and is.binary for the variables).
## To silence this warning:
## Call prp with roundint=FALSE,
## or rebuild the rpart model with model=TRUE.
prp(prune(arboles_bagged[[2]], cp =0.01))## Warning: Cannot retrieve the data used to build the model (so cannot determine roundint and is.binary for the variables).
## To silence this warning:
## Call prp with roundint=FALSE,
## or rebuild the rpart model with model=TRUE.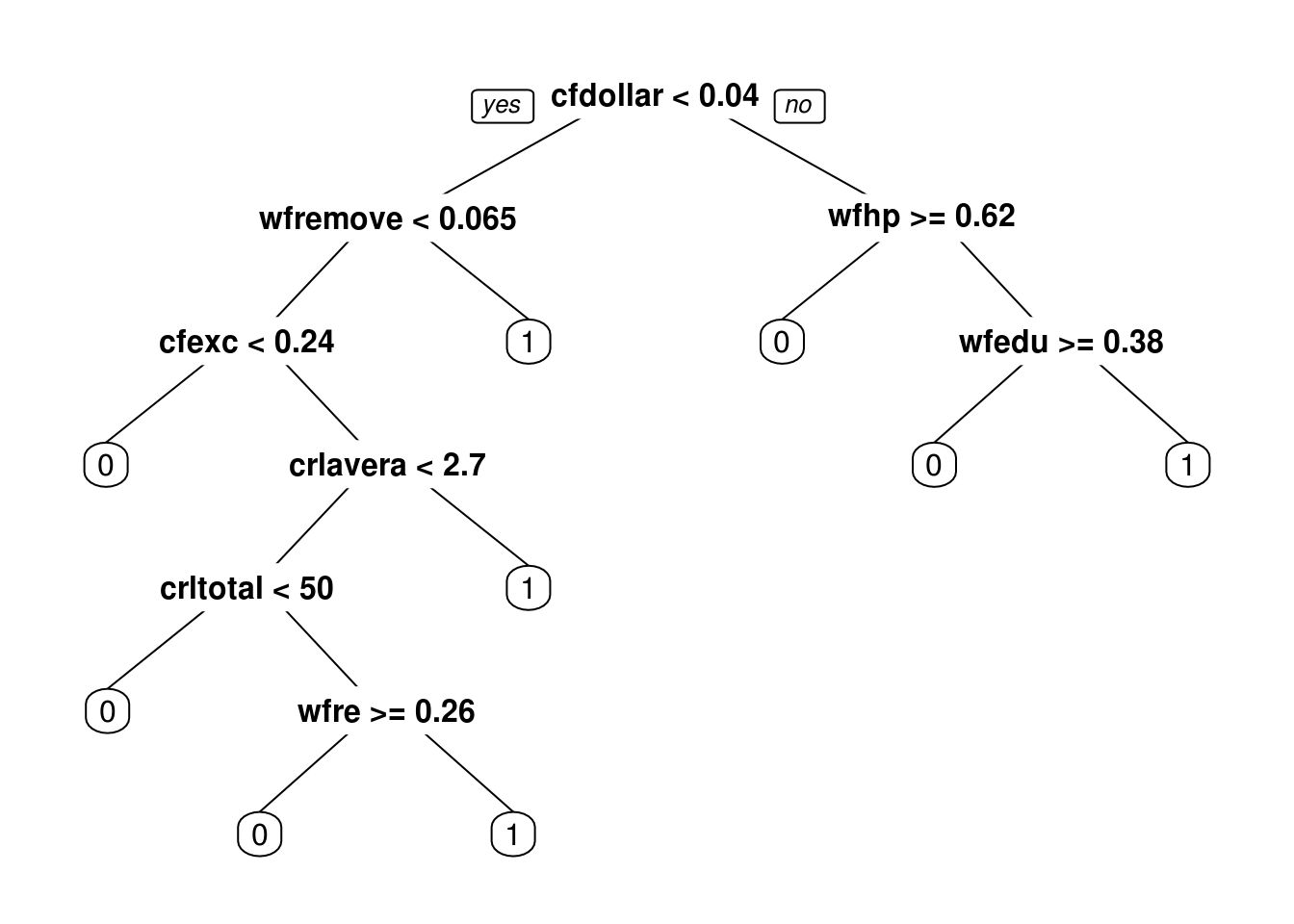
prp(prune(arboles_bagged[[3]], cp =0.01))## Warning: Cannot retrieve the data used to build the model (so cannot determine roundint and is.binary for the variables).
## To silence this warning:
## Call prp with roundint=FALSE,
## or rebuild the rpart model with model=TRUE.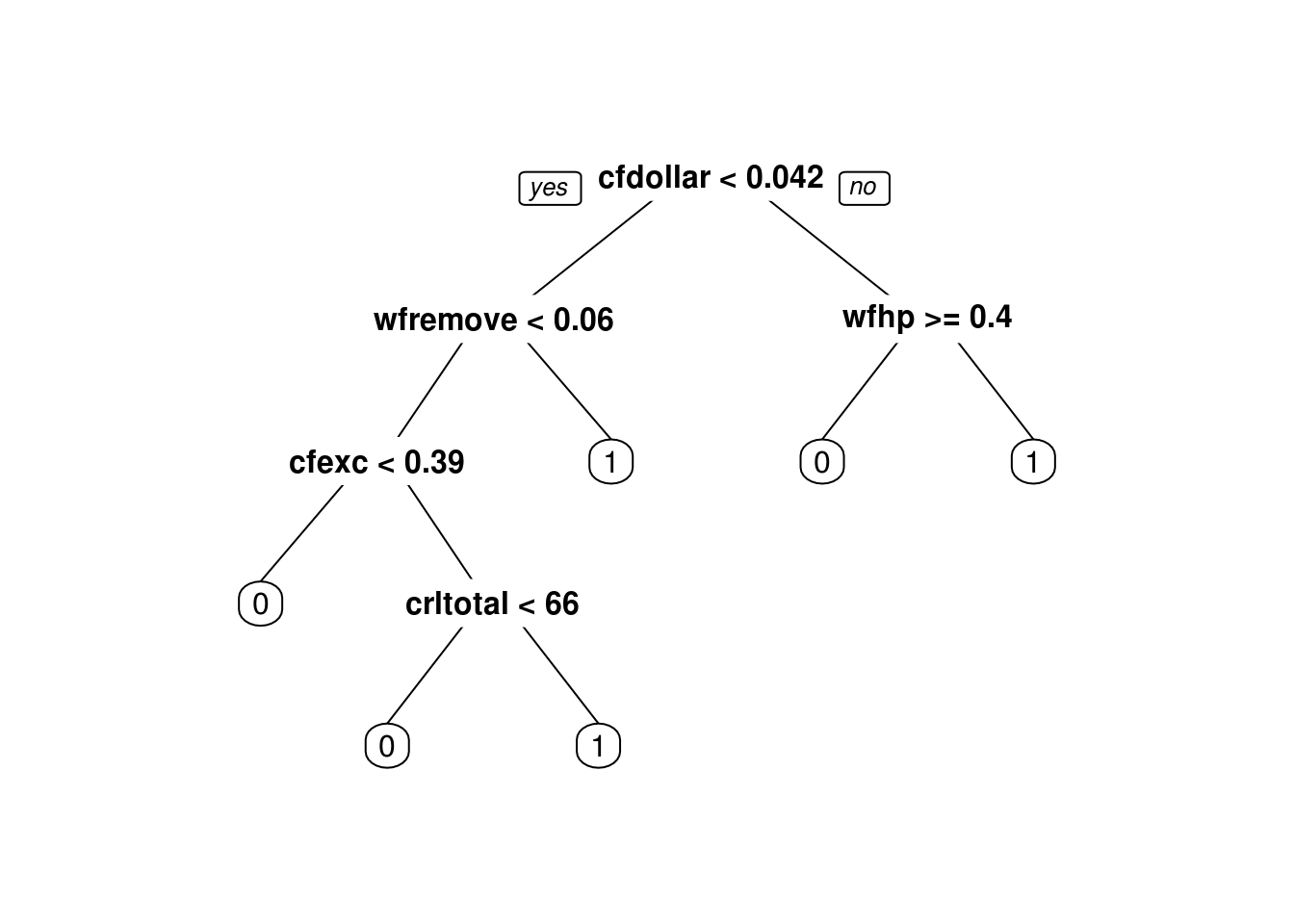 Ahora probemos hacer predicciones con los 30 árboles:
Ahora probemos hacer predicciones con los 30 árboles:
library(purrr)
preds_clase <- lapply(arboles_bagged, function(arbol){
preds <- predict(arbol, newdata = spam_prueba)[,2]
})
preds <- preds_clase %>% reduce(cbind)
dim(preds)## [1] 1534 30prop_bagging <- apply(preds, 1, mean)
prop.table(table(prop_bagging > 0.5, spam_prueba$spam),2)##
## 0 1
## FALSE 0.96224380 0.09555189
## TRUE 0.03775620 0.90444811Y vemos que tenemos una mejora inmediata con respecto un sólo árbol grande (tanto un árbol grande como uno podado con costo-complejidad). El único costo es el cómputo adicional para procesar las muestras bootstrap
- ¿Cuántas muestras bootstrap? Bagging generalmente funciona mejor cuando tomamos tantas muestras como sea posible - aunque también es un parámetro que se puede afinar.
- Bagging por sí solo se usa rara vez. El método más poderoso es bosques aleatorios, donde el proceso básico es bagging de árboles, pero añadimos ruido adicional en la construcción de árboles.
12.2.2 Mejorando bagging
El factor que limita la mejora de desempeño de bagging es que los árboles están correlacionados a través de la muestra de entrenamiento. Como vimos, si los árboles fueran independientes, entonces mejoramos por un factor de \(B\) (número de muestras independientes). Veamos un argumento para entender cómo esa correlación limita las mejoras:
Quiséramos calcular (para una \(x\) fija)
\[Var(T(x)) = Var\left(\frac{1}{B}\sum_{i=1}^B T^*_i\right)\]
donde cada \(T^*_i\) se construye a partir de una muestra bootstrap de \({\mathcal L}\). Nótese que esta varianza es sobre la muestra de entrenamiento \({\mathcal L}\). Usando la fórmula de la varianza para sumas generales: \[\begin{equation} Var(T(x)) = Var\left(\frac{1}{B}\sum_{i=1}^B T^*_i\right) = \sum_{i=1}^B \frac{1}{B^2} Var(T^*_i(x)) + \frac{2}{B^2}\sum_{i < j} Cov(T_i^* (x), T_j^* (x)) \tag{12.1} \end{equation}\]
Ponemos ahora
\[\sigma^2(x) = Var(T_i^* (x))\] que son todas iguales porque los árboles bootstrap se extraen de la misma manera (\({\mathcal L}\to {\mathcal L}^*\to T^*\)).
Escribimos ahora \[\rho(x) = corr(T_i^* (x), T_j^* (x))\] que es una correlación sobre \({\mathcal L}\) (asegúrate que entiendes este término). Todas estas correlaciones son iguales pues cada par de árboles se construye de la misma forma.
Así que la fórmula (12.1) queda
\[\begin{equation} Var(T(x)) = \frac{1}{B} \sigma^2(x) + \frac{B-1}{B} \rho(x)\sigma^2(x) = \sigma^2(x)\left(\frac{1}{B} + \left(1-\frac{1}{B}\right )\rho(x) \right) \tag{12.2} \end{equation}\]
En el límite (cuando B es muy grande, es decir, promediamos muchos árboles):
\[\begin{equation} Var(T(x)) = Var\left(\frac{1}{B}\sum_{i=1}^B T^*_i\right) \approx \sigma^2(x)\rho(x) \tag{12.3} \end{equation}\]
Si \(\rho(x)=0\) (árboles no correlacionados), la varianza del ensemble es la fracción \(1/B\) de la varianza de un solo árbol, y obtenemos una mejora considerable en varianza. En el otro extremo, si la correlación es alta \(\rho(x)\approx 1\), entonces no obtenemos ganancias por promediar árboles y la varianza del ensamble es similar a la de un solo árbol.
- Cuando hacemos bagging de árboles, la limitación de mejora cuando promediamos muchos árboles está dada por la correlación entre ellos: cuanto más grande es la correlación, menor beneficio en reducción de varianza obtenemos.
- Si alteramos el proceso para producir árboles menos correlacionados (menor \(\rho(x)\)), podemos mejorar el desempeño de bagging. Sin embargo, estas alteraciones generalmente están acompañadas de incrementos en la varianza (\(\sigma^x(x)\)).
12.3 Bosques aleatorios
Los bosques aleatorios son una versión de árboles de bagging decorrelacionados. Esto se logra introduciendo variabilidad en la construcción de los árboles (esto es paradójico - pero la explicación está arriba: aunque la varianza empeora (de cada árbol), la decorrelación de árboles puede valer la pena).
12.3.1 Sabiduría de las masas
Una explicación simple de este proceso que se cita frecuentemente es el fenómeno de la sabiduría de las masas: cuando promediamos estimaciones pobres de un gran número de personas (digamos ignorantes), obtenemos mejores estimaciones que cualquiera de las componentes individuales, o incluso mejores que estimaciones de expertos. Supongamos por ejemplo que \(G_1,G_2,\ldots, G_M\) son clasificadores débiles, por ejemplo \[P(correcto) = P(G_i=G)=0.6\] para un problema con probabilidad base \(P(G=1)=0.5\). Supongamos que los predictores son independientes, y sea \(G^*\) el clasificador que se construye por mayoría de votos a partir de \(G_1,G_2,\ldots, G_M\), es decir \(G^*=1\) si y sólo si \(\#\{ G_i = 1\} > M/2\).
Podemos ver que el número de aciertos (X) de \(G_1,G_2,\ldots, G_M\), por independencia, es binomial \(Bin(M, 0.6)\). Si \(M\) es grande, podemos aproximar esta distribución con una normal con media \(M*0.6\) y varianza \(0.6*0.4*M\). Esto implica que
\[P(G^* correcto)=P(X > 0.5M) \approx P\left( Z > \frac{0.5M-0.6M}{\sqrt(0.24M)}\right) = P\left(Z > -2.041 \sqrt{M}\right)\]
Y ahora observamos que cuando \(M\) es grande, la cantidad de la derecha tiende a 1: la masa, en promedio, tiene la razón!
Nótese, sin embargo, que baja dependencia entre las “opiniones” es parte crucial del argumento, es decir, las opiniones deben estar decorrelacionadas.
El proceso de decorrelación de bosques aleatorios consiste en que cada vez que tengamos que hacer un corte en un árbol de bagging, escoger al azar un número de variables y usar estas para buscar la mejor variable y el mejor punto de corte, como hicimos en la construcción de árboles.
Bosques aleatorios Sea \(m\) fija. Sea \({\mathcal L} =\{(x^{(i)}, y^{(i)})\}_{i=1}^n\) una muestra de entrenamiento, y sean \[{\mathcal L}_1^*, {\mathcal L}_2^*, \ldots, {\mathcal L}_B^*,\] muestras bootstrap de \({\mathcal L}\) (muestreamos con reemplazo los pares \((x^{(i)}, y^{(i)})\), para obtener una muestra de tamaño \(n\)).
- Para cada muestra bootstrap construimos un árbol \[{\mathcal L}_b^* \to T_b^*\] de la siguiente forma:
- En cada nodo candidato a particionar, escogemos al azar \(m\) variables de las disponibles
- Buscamos la mejor variable y punto de corte (como en un árbol normal) pero solo entre las variables que seleccionamos al azar.
- Seguimos hasta construir un árbol grande.
- (Regresión) Promediamos árboles para reducir varianza \[T^*(x) = \frac{1}{B}\sum_{i=b}^B T_b^*(x)\]
- (Clasificación) Tomamos votos sobre todos los árboles: \[T^*(x) = argmax_g \{ \# \{i|T_b^*(x)=g\}\}.\] Podemos también calcular probabilidades promedio sobre todos los árboles.
Bosques aleatorios muchas veces reduce el error de predicción gracias a una reducción a veces considerable de varianza. El objetivo final es reducir la varianza alta que producen árboles normales debido a la forma tan agresiva de construir sus cortes.
Observaciones:
- El número de variables \(m\) que se seleccionan en cada nodo es un parámetro que hay que escoger (usando validación, validación cruzada).
- Ojo: no se selecciona un conjunto de \(m\) variables para cada árbol. En la construcción de cada árbol, en cada nodo se seleccionan \(m\) variables como candidatas para cortes.
- Como inducimos aleatoriedad en la construcción de árboles, este proceso reduce la correlación entre árboles del bosque, aunque también incrementa su varianza. Los bosques aleatorios funcionan bien cuando la mejora en correlación es más grande que la pérdida en varianza.
- Reducir \(m\), a grandes rasgos:
- Aumenta el sesgo del bosque (pues es más restringido el proceso de construcción)
- Disminuye la correlación entre árboles y aumenta la varianza de cada árbol
- Intrementar \(m\)
- Disminuye el sesgo del bosque (menos restricción)
- Aumenta la correlacción entre árobles y disminuye la varianza de cada árbol
12.3.2 Ejemplo
Regresamos a nuestro ejemplo de spam. Intentemos con 500 árboles, y 6 variables (de 58 variables) para escoger como candidatos en cada corte:
library(randomForest)
bosque_spam <-randomForest(factor(spam) ~ ., data = spam_entrena,
ntree = 1500, mtry = 6, importance=TRUE)Evaluamos desempeño, donde vemos que obtenemos una mejora inmediata con respecto a bagging:
probas <- predict(bosque_spam, newdata = spam_prueba, type='prob')
head(probas)## 0 1
## 1 0.009333333 0.9906667
## 2 0.016666667 0.9833333
## 3 0.070000000 0.9300000
## 4 0.398666667 0.6013333
## 5 0.045333333 0.9546667
## 6 0.028666667 0.9713333prop_bosque <- probas[,2]
table(prop_bosque> 0.5, spam_prueba$spam) %>% prop.table(2) %>% round(3)##
## 0 1
## FALSE 0.971 0.092
## TRUE 0.029 0.908Comparemos las curvas ROC para:
- árbol grande sin podar
- árbol podado con costo-complejidad
- bagging de árboles
- bosque aleatorio
Las curvas de precision-recall
library(ROCR)
pred_arbol <- prediction(prop_arbol_grande[,2], spam_prueba$spam)
pred_podado <- prediction(prop_arbol_podado[,2], spam_prueba$spam)
pred_bagging <- prediction(prop_bagging, spam_prueba$spam)
pred_bosque <- prediction(prop_bosque, spam_prueba$spam)
preds_roc <- list(pred_arbol, pred_podado, pred_bagging, pred_bosque)
perfs <- lapply(preds_roc, function(pred){
performance(pred, x.measure = 'prec', measure = 'rec')
})
plot(perfs[[1]], lwd=2, xlim=c(0,1))
plot(perfs[[2]], add=TRUE, col='orange', lwd=2)
plot(perfs[[3]], add=TRUE, col='gray', lwd=2)
plot(perfs[[4]], add=TRUE, col='purple', lwd=2)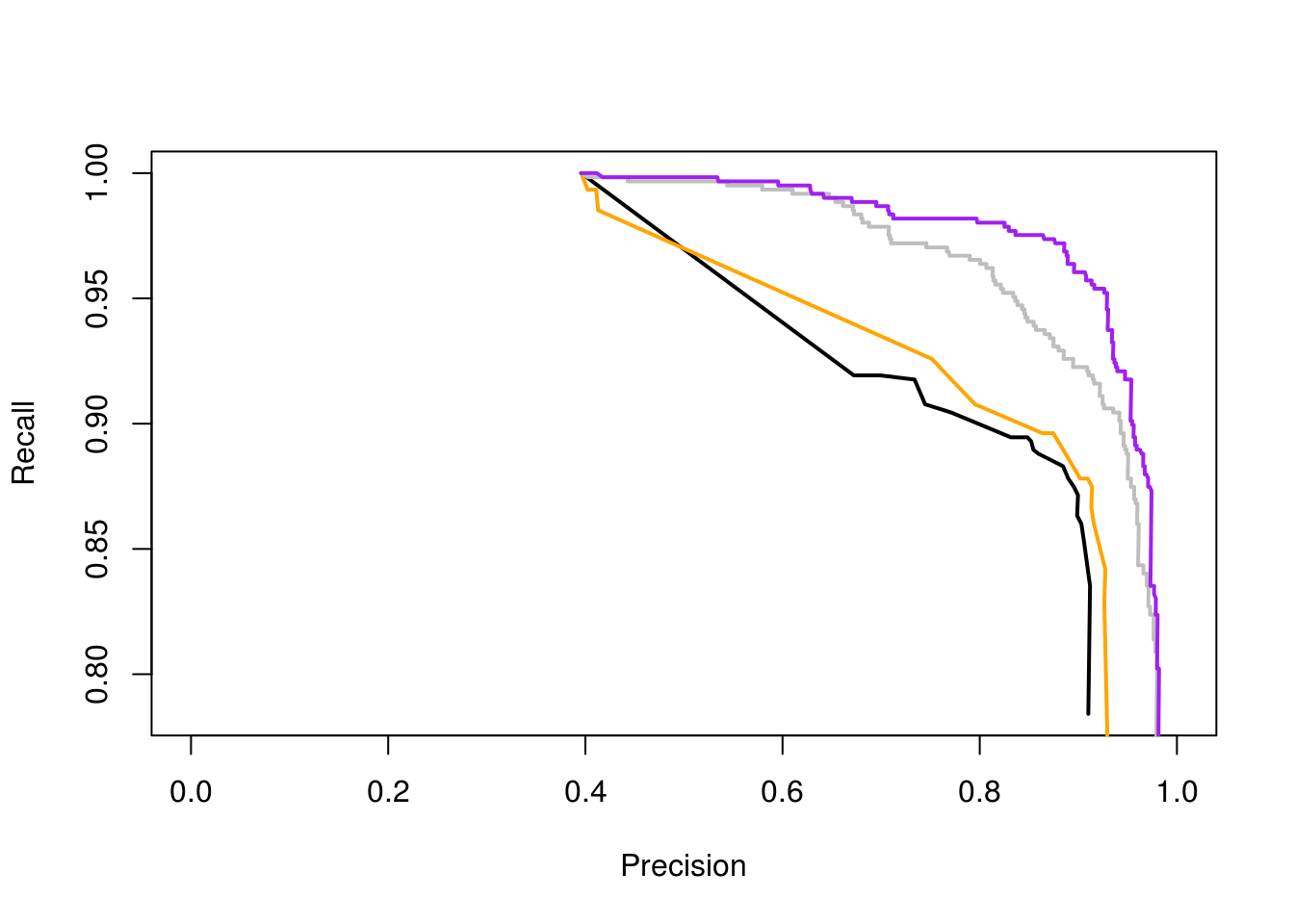
O las curvas ROC
perfs <- lapply(preds_roc, function(pred){
performance(pred, x.measure = 'fpr', measure = 'sens')
})
plot(perfs[[1]], lwd=2)
plot(perfs[[2]], add=TRUE, col='orange', lwd=2)
plot(perfs[[3]], add=TRUE, col='gray', lwd=2)
plot(perfs[[4]], add=TRUE, col='purple', lwd=2)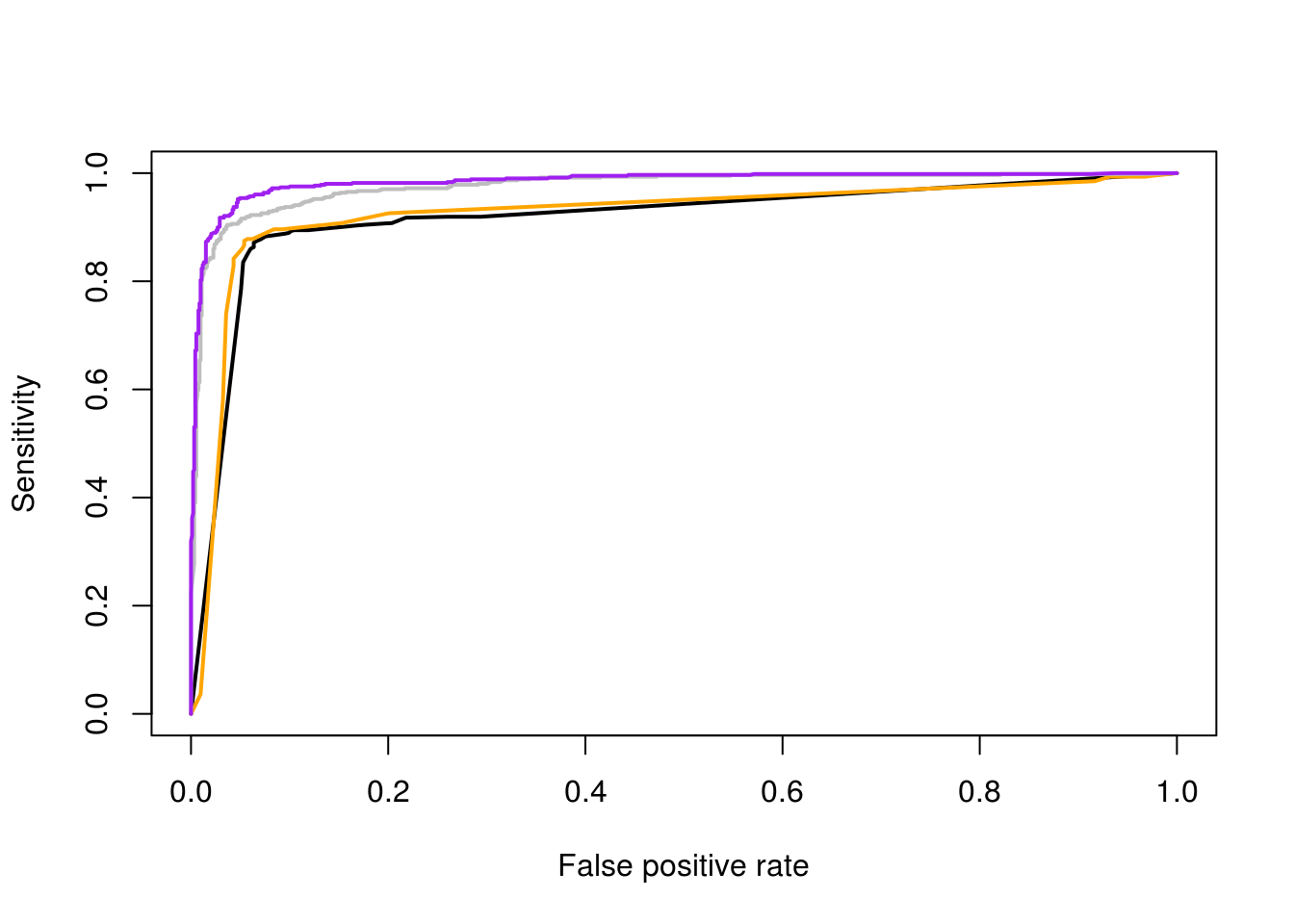
12.3.3 Más detalles de bosques aleatorios.
Los bosques aleatorios, por su proceso de construcción, tienen aspectos interesantes.
En primer lugar, tenemos la estimación de error de prueba Out-of-Bag (OOB), que es una estimación honesta del error de predicción basada en el proceso de bagging.
Obsérvese en primer lugar, que cuando tomamos muestras con reemplazo para construir cada árbol, algunos casos de entrenamiento aparecen más de una vez, y otros casos no se usan en la construcción del árbol. La idea es entonces es usar esos casos excluidos para hacer una estimación honesta del error.
Ejemplo
Si tenemos una muestra de entrenamiento
entrena <- data_frame(x=1:10, y=rnorm(10, 1:10, 5))
entrena## # A tibble: 10 x 2
## x y
## <int> <dbl>
## 1 1 0.936
## 2 2 -2.84
## 3 3 -5.63
## 4 4 -2.21
## 5 5 7.04
## 6 6 7.09
## 7 7 13.0
## 8 8 -0.423
## 9 9 10.4
## 10 10 5.03Tomamos una muestra bootstrap:
entrena_boot <- sample_n(entrena, 10, replace = TRUE)
entrena_boot## # A tibble: 10 x 2
## x y
## <int> <dbl>
## 1 7 13.0
## 2 10 5.03
## 3 2 -2.84
## 4 8 -0.423
## 5 2 -2.84
## 6 1 0.936
## 7 4 -2.21
## 8 10 5.03
## 9 8 -0.423
## 10 8 -0.423Construimos un predictor
mod_boot <- lm(y~x, data = entrena_boot)y ahora obtenemos los datos que no se usaron:
prueba_boot <- anti_join(entrena, entrena_boot)## Joining, by = c("x", "y")prueba_boot## # A tibble: 4 x 2
## x y
## <int> <dbl>
## 1 3 -5.63
## 2 5 7.04
## 3 6 7.09
## 4 9 10.4y usamos estos tres casos para estimar el error de predicción:
mean(abs(predict(mod_boot, prueba_boot)-prueba_boot$y))## [1] 5.936181Esta es la estimación OOB (out-of-bag) para este modelo particular.
En un principio podemos pensar que quizá por mala suerte obtenemos pocos elementos OOB para evaluar el error, pero en realidad para muestras no tan chicas obtenemos una fracción considerable.
Demuestra usando probabilidad y teoría de muestras con reemplazo.
Estimación OOB del error
Consideramos un bosque aleatorio \(T_{ba}\)con árboles \(T_1^*, T_2^*, \ldots, T_B^*\), y conjunto de entrenamiento original \({\mathcal L} =\{(x^{(i)}, y^{(i)}\}_{i=1}^n\). Para cada caso de entrenamiento \((x^{(i)}, y^{(i)})\) consideramos todos los árboles que no usaron este caso para construirse, y construimos un bosque \(T_{ba}^{(i)}\) basado solamente en esos árboles. La predicción OOB de \(T_{ba}^{(i)}\) para \((x^{(i)}, y^{(i)})\) es \[y_{oob}^{(i)} = T_{ba}^{(i)}(x^{(i)})\] El error OOB del árbol \(T_{ba}\) está dado por 1. Regresión (error cuadrático medio) \[\hat{Err}_{oob} = \frac{1}{n} \sum_{i=1}^n (y^{(i)} - y_{oob}^{(i)})^2\] 2. Clasificación (error de clasificación) \[\hat{Err}_{oob} = \frac{1}{n}\sum_{i=1}^n I(y^{(i)} = y_{oob}^{(i)})\]
- Para cada dato de entrenamiento, hacemos predicciones usando solamente los árboles que no consideraron ese dato en su construcción. Estas predicciones son las que evaluamos
- Es una especie de validación cruzada (se puede demostrar que es similar a validacion cruzada leave-one-out), pero es barata en términos computacionales.
- Como discutimos en validación cruzada, esto hace de OOB una buena medida de error para afinar los parámetros del modelo (principalmente el número \(m\) de variables que se escogen en cada corte).
Ejempo
Para el ejemplo de spam, podemos ver el error OOB ( y matriz de confusión también OOB):
bosque_spam##
## Call:
## randomForest(formula = factor(spam) ~ ., data = spam_entrena, ntree = 1500, mtry = 6, importance = TRUE)
## Type of random forest: classification
## Number of trees: 1500
## No. of variables tried at each split: 6
##
## OOB estimate of error rate: 4.96%
## Confusion matrix:
## 0 1 class.error
## 0 1807 54 0.02901666
## 1 98 1108 0.08126036Que comparamos con
probas <- predict(bosque_spam, newdata = spam_prueba, type='prob')
prop_bosque <- probas[,2]
tab <- table(prop_bosque> 0.5, spam_prueba$spam) %>% prop.table(2) %>% round(3)
1-diag(tab)## [1] 0.029 0.092Podemos comparar con el cálculo de entrenamiento, que como sabemos típicamente es una mala estimación del error de predicción:
probas <- predict(bosque_spam, newdata = spam_entrena, type='prob')
prop_bosque <- probas[,2]
table(prop_bosque> 0.5, spam_entrena$spam)##
## 0 1
## FALSE 1861 11
## TRUE 0 1195tab <- table(prop_bosque> 0.5, spam_entrena$spam) %>% prop.table(2) %>% round(3)
1-diag(tab)## [1] 0.000 0.009Podemos también monitorear el error OOB conforme agregamos más árboles. Esta gráfica es útil para entender qué tanto esta mejorando el bosque dependiendo del número de árboles:
err_spam <- bosque_spam$err.rate %>% as_data_frame %>% mutate(ntrees = row_number())
head(err_spam)## # A tibble: 6 x 4
## OOB `0` `1` ntrees
## <dbl> <dbl> <dbl> <int>
## 1 0.113 0.0851 0.159 1
## 2 0.113 0.0853 0.160 2
## 3 0.109 0.0786 0.158 3
## 4 0.101 0.0744 0.143 4
## 5 0.102 0.0715 0.149 5
## 6 0.0972 0.0712 0.137 6err_spam <- err_spam %>% gather(métrica, valor, -ntrees)
ggplot(err_spam, aes(x=ntrees, y=valor, colour=métrica)) + geom_line()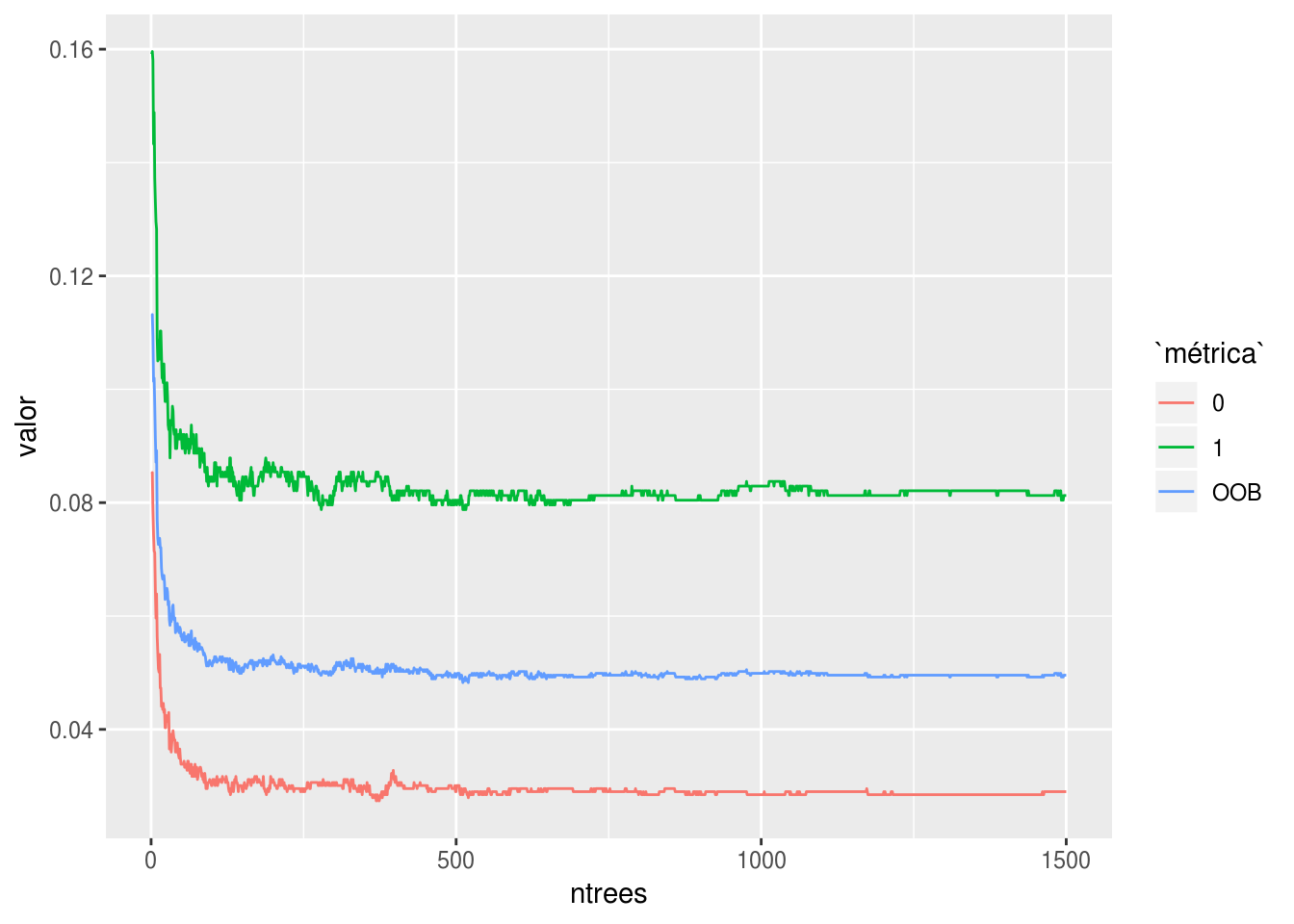
Además de la estimación OOB del error de clasificación, en la gráfica están las estimaciones OOB dada cada una de las clases (probabilidad de clasificar correctamente dada la clase: en problemas binarios son tasa de falsos positivos y tasa de falsos negativos).
12.3.4 Importancia de variables
Usando muestras bootstrap y error OOB, es posible tener mediciones útiles de la importancia de una variable en el modelo en un bosque aleatorio (todo esto también fue inventado por Breiman).
En primer lugar, consideremos qué significa que una variable sea importante desde el punto predictivo en un modelo. Podemos considerar, por ejemplo:
- Si quitamos una variable, y el error de predicción se degrada, la variable es importante. Este no es un muy buen enfoque, porque muchas veces tenemos conjuntos de variables correlacionadas. Aún cuando una variable influya en la predicción, si la quitamos, otras variable pueden hacer su trabajo, y el modelo no se degrada mucho (piensa en regresión, en donde incluso esta variable eliminada puede tener un coeficiente grande e influir mucho en la predicción). También requiere ajustar modelos adicionales.
- Si las predicciones cambian mucho cuando una variable cambia, entonces la variable es importante. Este concepto funciona mejor, al menos desde el punto de vista predictivo. Su defecto es que debemos decidir qué cambios queremos medir. Si el modelo es simple (por ejemplo, lineal), entonces es relativamente fácil usar cambios marginales. Pero en modelos no lineales cambios marginales no necesariamente evalúan correctamente el efecto de la variable sobre las predicciones. La situación se complica adicionalmente si hay interacciones con otras variables, lo que típicamente sucede en métodos basados en árbles.
La idea de Breiman, que intenta atender estas observaciones, es como sigue:
Consideramos un árbol \(T^*_j\) del bosque, con muestra bootstrap \({\mathcal L}^*_i\). Calculamos un tipo de error out-of-bag para el árbol, promediando sobre todos los elementos de \({\mathcal L}\) que no están en \({\mathcal L}^*_i\)
\[\widehat{Err}_{oob}(T^*_j) = \frac{1}{A_j}\sum_{(x^{(i)}, y^{(i)}) \in {\mathcal L} -{\mathcal L}^*_i} L(y^{(i)}, T^*_j(x^{(i)}))\] donde \(A_j\) es el tamaño de \({\mathcal L} -{\mathcal L}^*_i\).
Ahora permutamos al azar la variable \(X_k\) en la muestra OOB \({\mathcal L} -{\mathcal L}^*_i\). Describimos esta operación como \(x^{(i)} \to x^{(i)}_k\). Calculamos el error nuevamente:
\[\widehat{Err}_{k}(T^*_j) = \frac{1}{A_j}\sum_{(x^{(i)}, y^{(i)}) \in {\mathcal L} -{\mathcal L}^*_i} L(y^{(i)}, T^*_j(x_k^{(i)}))\] Ahora calculamos la degradación del error out-of-bag debido a la permutación: \[ D_k(T_j^*) = \widehat{Err}_{k}(T^*_j) - \widehat{Err}_{oob}(T^*_j) \]
Y promediamos sobre el bosque entero \[I_k =\frac{1}{B} \sum_{j=1}^B D_k(T^*_j)\] y a esta cantidad le llamamos la importancia (basada en permutaciones) de la variable \(k\) en el bosque aleatorio. Es el decremento promedio de capacidad predictiva cuando “quitamos” la variable \(X_k\).
Nótese que:
- No podemos “quitar” la variable durante el entrenamiento de los árboles, pues entonces otras variables pueden hacer su trabajo, subestimando su importancia.
- No podemos “quitar” la variable al medir el error OOB, pues se necesitan todas las variables para poder clasificar con cada árbol (pues cada árbol usa esa variable, o tiene probabilidad de usarla).
- Pero podemos permutar a la hora calcular el error OOB (y no durante el entrenamiento), rompiendo la relación que hay entre \(X_k\) y la variable respuesta.
- Aunque podríamos usar esta medida para árboles, no es muy buena idea por el problema de “enmascaramiento”. Este problema se aminora en los bosques aleatorios pues todas las variables tienen oportunidad de aportar cortes en ausencia de otras variables.
Otra manera de medir importancia para árboles de regresión y clasificación es mediante el decremento de impureza promedio sobre el bosque, para cada variable.
- Cada vez que una variable aporta un corte en un árbol, la impureza del árbol disminuye.
- Sumamos, en cada árbol, todos estos decrementos de impureza (cada vez que aparece la variable en un corte)
- Finalmente, promediamos esta medida de importancia dentro de cada árbol sobre el bosque completo.
- Repetimos para cada variable.
Para árboles de clasificación, usualmente se toma la importancia de Gini, que está basada in la impureza de Gini en lugar de la entropía. La impureza de Gini está dada por \[I_G(p_1, \ldots, p_K) = \sum_{k=1}^K p_k(1-p_k),\] que es similar a la impureza de entropía que discutimos en la construcción de árboles: \[I_G(p_1, \ldots, p_K) = \sum__{k=1}^K -p_k\log (p_k),\] Nótese por ejemplo que ambas toman su valor máximo en \(p_k=1/K\) (distribución más uniforme posible sobre las clases), y que son iguales a cero cuando \(p_k=1\) para alguna \(k\). #### Ejemplo{-} En nuestro ejemplo de spam
imp <- importance(bosque_spam, type=1)
importancia_df <- data_frame(variable = rownames(imp), MeanDecreaseAccuracy = imp[,1]) %>%
arrange(desc(MeanDecreaseAccuracy))
importancia_df## # A tibble: 58 x 2
## variable MeanDecreaseAccuracy
## <chr> <dbl>
## 1 cfexc 73.2
## 2 wfremove 63.1
## 3 crlaverage 63.0
## 4 cfdollar 60.3
## 5 wfhp 55.2
## 6 crllongest 54.7
## 7 wffree 54.3
## 8 crltotal 52.0
## 9 wfedu 47.8
## 10 wfyour 45.3
## # ... with 48 more rowsimportancia_df <- importancia_df %>% mutate(variable = reorder(variable, MeanDecreaseAccuracy))
ggplot(importancia_df , aes(x=variable, y= MeanDecreaseAccuracy)) + geom_point() +
coord_flip()
Observación: en el paquete randomForest, las importancias están escaladas por su la desviación estándar sobre los árboles - la idea es que puedan ser interpretados como valores-\(z\) (estandarizados). En este caso, nos podríamos fijar en importancias que están por arriba de \(2\), por ejemplo. Para obtener los valores no estandarizados (y ver la degradación en desempeño directamente) podemos calcular
importance(bosque_spam, type = 1, scale = FALSE)## MeanDecreaseAccuracy
## X -3.398063e-04
## wfmake 7.820918e-04
## wfaddress 1.509922e-03
## wfall 3.607607e-03
## wf3d 6.865265e-05
## wfour 1.415974e-02
## wfover 2.559785e-03
## wfremove 3.466735e-02
## wfinternet 5.113536e-03
## wforder 1.229169e-03
## wfmail 2.388153e-03
## wfreceive 4.081920e-03
## wfwill 3.701128e-03
## wfpeople 6.623610e-04
## wfreport 6.582026e-04
## wfaddresses 8.486423e-04
## wffree 2.377365e-02
## wfbusiness 5.742176e-03
## wfemail 2.207889e-03
## wfyou 1.151620e-02
## wfcredit 3.088054e-03
## wfyour 1.909754e-02
## wffont 1.687250e-03
## wf000 1.358799e-02
## wfmoney 1.171880e-02
## wfhp 3.220300e-02
## wfhpl 1.321378e-02
## wfgeorge 1.677690e-02
## wf650 3.714641e-03
## wflab 1.205268e-03
## wflabs 2.968365e-03
## wftelnet 1.252834e-03
## wf857 5.362343e-04
## wfdata 8.375305e-04
## wf415 4.832454e-04
## wf85 2.268768e-03
## wftechnology 1.603492e-03
## wf1999 6.902904e-03
## wfparts 7.131246e-05
## wfpm 1.255157e-03
## wfdirect 6.650049e-04
## wfcs 5.034624e-04
## wfmeeting 3.209452e-03
## wforiginal 8.825843e-04
## wfproject 6.864723e-04
## wfre 4.000573e-03
## wfedu 1.049319e-02
## wftable 2.721772e-05
## wfconference 4.790163e-04
## cfsc 1.527800e-03
## cfpar 4.051610e-03
## cfbrack 9.434229e-04
## cfexc 3.979771e-02
## cfdollar 3.244195e-02
## cfpound 9.215076e-04
## crlaverage 2.784469e-02
## crllongest 3.617719e-02
## crltotal 3.151068e-0212.3.5 Ajustando árboles aleatorios.
- El parámetro más importante de afinar es usualmente \(m\), el número de variables que se escogen al azar en cada nodo.
- A veces podemos obtener algunas ventajas de afinar el número mínimo de observaciones por nodo terminal y/o el número mínimo de observaciones por nodo para considerar hacer cortes adicionales
- Usualmente corremos tantos árboles como podamos (cientos, miles), o hasta que se estabiliza el error. Aumentar más arboles rara vez producen sobreajuste adicional (aunque esto no quiere decir que los bosques aleatorios no puedan sobreajustar!)
Ejemplo
Consideremos datos de (casas en venta en Ames, Iowa)[https://ww2.amstat.org/publications/jse/v19n3/decock.pdf]. Queremos predecir el precio listado de una casa en función de las características de las casa.
El análisis completo (desde limpieza y exploración) está en scripts/bosque-housing.Rmd
12.3.6 Ventajas y desventajas de bosques aleatorios
Ventajas:
- Entre los métodos estándar, es en general uno de los métodos más competitivos: usualmente tienen excelentes tasas muy buenas de error de predicción.
- Los bosques aleatorios son relativamente fáciles de entrenar (ajustar usualmente 1 o 2 parámetros) y rápidos de ajustar.
- Heredan las ventajas de los árboles: no hay necesidad de transformar variables o construir interacciones (pues los árboles pueden descubrirlas), son robustos a valores atípicos.
- Igual que con los árboles, las predicciones de los bosques siempre están en el rango de las variables de predicción (no extrapolan)
Desventajas: - Pueden ser lentos en la predicción, pues muchas veces requieren evaluar grandes cantidades de árboles. - No es tan simple adaptarlos a distintos tipos de problemas (por ejemplo, como redes neuronales, que combinando capas podemos construir modelos ad-hoc a problemas particulares). - La falta de extrapolación puede ser también un defecto (por ejemplo, cuando hay una estructura lineal aproximada).