Clase 10 Diagnóstico y mejora de modelos
10.1 Aspectos generales
Al comenzar un proyecto de machine learning, las primeras consideraciones deben ser:
Establecer métricas de error apropiadas para el problema, y cuál es el máximo valor de este error requerido para nuestra aplicación.
- Construir un pipeline lo antes posible que vaya de datos hasta medición de calidad de los modelos. Este pipeline deberá, al menos, incluir cálculos de entradas, medición de desempeño de los modelos y cálculos de otros diagnósticos (como error de entrenamiento, convergencia de algoritmos, etc.)
En general, es difícil preveer exactamente qué va a funcionar para un problema particular, y los diagnósticos que veremos requieren de haber ajustado modelos. Nuestra primera recomendación para ir hacia un modelo de mejor desempeño es:
Es mejor y más rápido comenzar rápido, aún con un modelo simple, con entradas {} (no muy refinadas), y con los datos que tenemos a mano. De esta forma podemos aprender más rápido. Demasiado tiempo pensando, discutiendo, o diseñando qué algoritmo deberíamos usar, cómo deberíamos construir las entradas, etc. es muchas veces tiempo perdido.
Con el pipeline establecido, si el resultado no es satisfactorio, entonces tenemos que tomar decisiones para mejorar.
10.2 ¿Qué hacer cuando el desempeño no es satisfactorio?
Supongamos que tenemos un clasificador construido con regresión logística regularizada, y que cuando lo aplicamos a nuestra muestra de prueba el desempeño es malo. ¿Qué hacer?
Algunas opciones:
- Conseguir más datos de entrenamiento.
- Reducir el número de entradas por algún método (eliminación manual, componentes principales, etc.)
- Construir más entradas utilizando distintos enfoques o fuentes de datos.
- Incluir variables derivadas adicionales e interacciones.
- Intentar construir una red neuronal para predecir (otro método).
- Aumentar la regularización.
- Disminuir la regularización.
- Correr más tiempo el algoritmo de ajuste.
¿Con cuál empezar? Cada una de estas estrategias intenta arreglar distintos problemas. En lugar de intentar al azar distintas cosas, que consumen tiempo y dinero y no necesariamente nos van a llevar a mejoras, a continuación veremos diagnósticos y recetas que nos sugieren la mejor manera de usar nuestro tiempo para mejorar nuestros modelos.
Usaremos el siguiente ejemplo para ilustrar los conceptos:
Ejemplo
Nos interesa hacer una predicción de polaridad de críticas o comentarios de pelíıculas: buscamos clasificar una reseña como positiva o negativa dependiendo de su contenido. Tenemos dos grupos de reseñas separadas en positivas y negativas (estos datos fueron etiquetados por una persona).
Cada reseña está un archivo de texto, y tenemos 1000 de cada tipo:
negativos <- list.files('./datos/sentiment/neg', full.names = TRUE)
positivos <- list.files('./datos/sentiment/pos', full.names = TRUE)
head(negativos)## [1] "./datos/sentiment/neg/cv000_29416.txt"
## [2] "./datos/sentiment/neg/cv001_19502.txt"
## [3] "./datos/sentiment/neg/cv002_17424.txt"
## [4] "./datos/sentiment/neg/cv003_12683.txt"
## [5] "./datos/sentiment/neg/cv004_12641.txt"
## [6] "./datos/sentiment/neg/cv005_29357.txt"head(positivos)## [1] "./datos/sentiment/pos/cv000_29590.txt"
## [2] "./datos/sentiment/pos/cv001_18431.txt"
## [3] "./datos/sentiment/pos/cv002_15918.txt"
## [4] "./datos/sentiment/pos/cv003_11664.txt"
## [5] "./datos/sentiment/pos/cv004_11636.txt"
## [6] "./datos/sentiment/pos/cv005_29443.txt"length(negativos)## [1] 1000length(positivos)## [1] 1000read_file(negativos[1])[1] “plot : two teen couples go to a church party , drink and then drive . get into an accident . of the guys dies , but his girlfriend continues to see him in her life , and has nightmares . ’s the deal ? the movie and " sorta " find out . . . : a mind-fuck movie for the teen generation that touches on a very cool idea , but presents it in a very bad package . is what makes this review an even harder one to write , since i generally applaud films which attempt to break the mold , mess with your head and such ( lost highway & memento ) , but there are good and bad ways of making all types of films , and these folks just didn’t snag this one correctly . seem to have taken this pretty neat concept , but executed it terribly . what are the problems with the movie ? , its main problem is that it’s simply too jumbled . starts off " normal " but then downshifts into this " fantasy " world in which you , as an audience member , have no idea what’s going on . are dreams , there are characters coming back from the dead , there are others who look like the dead , there are strange apparitions , there are disappearances , there are a looooot of chase scenes , there are tons of weird things that happen , and most of it is simply not explained . i personally don’t mind trying to unravel a film every now and then , but when all it does is give me the same clue over and over again , i get kind of fed up after a while , which is this film’s biggest problem . ’s obviously got this big secret to hide , but it seems to want to hide it completely until its final five minutes . do they make things entertaining , thrilling or even engaging , in the meantime ? really . sad part is that the arrow and i both dig on flicks like this , so we actually figured most of it out by the half-way point , so all of the strangeness after that did start to make a little bit of sense , but it still didn’t the make the film all that more entertaining . guess the bottom line with movies like this is that you should always make sure that the audience is " into it " even before they are given the secret password to enter your world of understanding . mean , showing melissa sagemiller running away from visions for about 20 minutes throughout the movie is just plain lazy ! ! , we get it . . . there people chasing her and we don’t know who they are . we really need to see it over and over again ? about giving us different scenes offering further insight into all of the strangeness going down in the movie ? , the studio took this film away from its director and chopped it up themselves , and it shows . might’ve been a pretty decent teen mind-fuck movie in here somewhere , but i guess " the suits " decided that turning it into a music video with little edge , would make more sense . actors are pretty good for the most part , although wes bentley just seemed to be playing the exact same character that he did in american beauty , only in a new neighborhood . my biggest kudos go out to sagemiller , who holds her own throughout the entire film , and actually has you feeling her character’s unraveling . , the film doesn’t stick because it doesn’t entertain , it’s confusing , it rarely excites and it feels pretty redundant for most of its runtime , despite a pretty cool ending and explanation to all of the craziness that came before it . , and by the way , this is not a horror or teen slasher flick . . . it’s packaged to look that way because someone is apparently assuming that the genre is still hot with the kids . also wrapped production two years ago and has been sitting on the shelves ever since . . . . skip ! ’s joblo coming from ? nightmare of elm street 3 ( 7/10 ) - blair witch 2 ( 7/10 ) - the crow ( 9/10 ) - the crow : salvation ( 4/10 ) - lost highway ( 10/10 ) - memento ( 10/10 ) - the others ( 9/10 ) - stir of echoes ( 8/10 ) ”
read_file(positivos[1])[1] “films adapted from comic books have had plenty of success , whether they’re about superheroes ( batman , superman , spawn ) , or geared toward kids ( casper ) or the arthouse crowd ( ghost world ) , but there’s never really been a comic book like from hell before . starters , it was created by alan moore ( and eddie campbell ) , who brought the medium to a whole new level in the mid ‘80s with a 12-part series called the watchmen . say moore and campbell thoroughly researched the subject of jack the ripper would be like saying michael jackson is starting to look a little odd . book ( or " graphic novel , " if you will ) is over 500 pages long and includes nearly 30 more that consist of nothing but footnotes . other words , don’t dismiss this film because of its source . you can get past the whole comic book thing , you might find another stumbling block in from hell’s directors , albert and allen hughes . the hughes brothers to direct this seems almost as ludicrous as casting carrot top in , well , anything , but riddle me this : who better to direct a film that’s set in the ghetto and features really violent street crime than the mad geniuses behind menace ii society ? ghetto in question is , of course , whitechapel in 1888 london’s east end . ’s a filthy , sooty place where the whores ( called " unfortunates " ) are starting to get a little nervous about this mysterious psychopath who has been carving through their profession with surgical precision . the first stiff turns up , copper peter godley ( robbie coltrane , the world is not enough ) calls in inspector frederick abberline ( johnny depp , blow ) to crack the case . , a widower , has prophetic dreams he unsuccessfully tries to quell with copious amounts of absinthe and opium . arriving in whitechapel , he befriends an unfortunate named mary kelly ( heather graham , say it isn’t so ) and proceeds to investigate the horribly gruesome crimes that even the police surgeon can’t stomach . don’t think anyone needs to be briefed on jack the ripper , so i won’t go into the particulars here , other than to say moore and campbell have a unique and interesting theory about both the identity of the killer and the reasons he chooses to slay . the comic , they don’t bother cloaking the identity of the ripper , but screenwriters terry hayes ( vertical limit ) and rafael yglesias ( les mis ? rables ) do a good job of keeping him hidden from viewers until the very end . ’s funny to watch the locals blindly point the finger of blame at jews and indians because , after all , an englishman could never be capable of committing such ghastly acts . from hell’s ending had me whistling the stonecutters song from the simpsons for days ( " who holds back the electric car/who made steve guttenberg a star ? " ) . ’t worry - it’ll all make sense when you see it . onto from hell’s appearance : it’s certainly dark and bleak enough , and it’s surprising to see how much more it looks like a tim burton film than planet of the apes did ( at times , it seems like sleepy hollow 2 ) . print i saw wasn’t completely finished ( both color and music had not been finalized , so no comments about marilyn manson ) , but cinematographer peter deming ( don’t say a word ) ably captures the dreariness of victorian-era london and helped make the flashy killing scenes remind me of the crazy flashbacks in twin peaks , even though the violence in the film pales in comparison to that in the black-and-white comic . winner martin childs’ ( shakespeare in love ) production design turns the original prague surroundings into one creepy place . the acting in from hell is solid , with the dreamy depp turning in a typically strong performance and deftly handling a british accent . holm ( joe gould’s secret ) and richardson ( 102 dalmatians ) log in great supporting roles , but the big surprise here is graham . cringed the first time she opened her mouth , imagining her attempt at an irish accent , but it actually wasn’t half bad . film , however , is all good . 2 : 00 - r for strong violence/gore , sexuality , language and drug content ”
Consideremos primero la métrica de error, que depende de nuestra aplicación. En este caso, quisiéramos hacer dar una calificación a cada película basada en el % de reseñas positivas que tiene. Supongamos que se ha decidido que necesitamos al menos una tasa de correctos de 90% para que el score sea confiable (cómo calcularías algo así?).
Ahora necesitamos construir un pipeline para obtener las primeras predicciones. Tenemos que pensar qué entradas podríamos construir.
10.3 Pipeline de procesamiento
Empezamos por construir funciones para leer datos (ver script). Construimos un data frame:
source('./scripts/funciones_sentiment.R')
df <- prep_df('./datos/sentiment/') %>% unnest(texto)
nrow(df)[1] 2000
df$texto[1][1] “Review films adapted from comic books have had plenty of success , whether they’re about superheroes ( batman , superman , spawn ) , or geared toward kids ( casper ) or the arthouse crowd ( ghost world ) , but there’s never really been a comic book like from hell before . for starters , it was created by alan moore ( and eddie campbell ) , who brought the medium to a whole new level in the mid ‘80s with a 12-part series called the watchmen . to say moore and campbell thoroughly researched the subject of jack the ripper would be like saying michael jackson is starting to look a little odd . the book ( or " graphic novel , " if you will ) is over 500 pages long and includes nearly 30 more that consist of nothing but footnotes . in other words , don’t dismiss this film because of its source . if you can get past the whole comic book thing , you might find another stumbling block in from hell’s directors , albert and allen hughes . getting the hughes brothers to direct this seems almost as ludicrous as casting carrot top in , well , anything , but riddle me this : who better to direct a film that’s set in the ghetto and features really violent street crime than the mad geniuses behind menace ii society ? the ghetto in question is , of course , whitechapel in 1888 london’s east end . it’s a filthy , sooty place where the whores ( called " unfortunates " ) are starting to get a little nervous about this mysterious psychopath who has been carving through their profession with surgical precision . when the first stiff turns up , copper peter godley ( robbie coltrane , the world is not enough ) calls in inspector frederick abberline ( johnny depp , blow ) to crack the case . abberline , a widower , has prophetic dreams he unsuccessfully tries to quell with copious amounts of absinthe and opium . upon arriving in whitechapel , he befriends an unfortunate named mary kelly ( heather graham , say it isn’t so ) and proceeds to investigate the horribly gruesome crimes that even the police surgeon can’t stomach . i don’t think anyone needs to be briefed on jack the ripper , so i won’t go into the particulars here , other than to say moore and campbell have a unique and interesting theory about both the identity of the killer and the reasons he chooses to slay . in the comic , they don’t bother cloaking the identity of the ripper , but screenwriters terry hayes ( vertical limit ) and rafael yglesias ( les mis ? rables ) do a good job of keeping him hidden from viewers until the very end . it’s funny to watch the locals blindly point the finger of blame at jews and indians because , after all , an englishman could never be capable of committing such ghastly acts . and from hell’s ending had me whistling the stonecutters song from the simpsons for days ( " who holds back the electric car/who made steve guttenberg a star ? " ) . don’t worry - it’ll all make sense when you see it . now onto from hell’s appearance : it’s certainly dark and bleak enough , and it’s surprising to see how much more it looks like a tim burton film than planet of the apes did ( at times , it seems like sleepy hollow 2 ) . the print i saw wasn’t completely finished ( both color and music had not been finalized , so no comments about marilyn manson ) , but cinematographer peter deming ( don’t say a word ) ably captures the dreariness of victorian-era london and helped make the flashy killing scenes remind me of the crazy flashbacks in twin peaks , even though the violence in the film pales in comparison to that in the black-and-white comic . oscar winner martin childs’ ( shakespeare in love ) production design turns the original prague surroundings into one creepy place . even the acting in from hell is solid , with the dreamy depp turning in a typically strong performance and deftly handling a british accent . ians holm ( joe gould’s secret ) and richardson ( 102 dalmatians ) log in great supporting roles , but the big surprise here is graham . i cringed the first time she opened her mouth , imagining her attempt at an irish accent , but it actually wasn’t half bad . the film , however , is all good . 2 : 00 - r for strong violence/gore , sexuality , language and drug content”
Ahora separamos una muestra de prueba (y una de entrenamiento más chica para simular después el proceso de recoger más datos):
set.seed(94512)
df$muestra <- sample(c('entrena', 'prueba'), 2000, prob = c(0.8, 0.2),
replace = TRUE)
table(df$muestra)##
## entrena prueba
## 1575 425df_ent <- df %>% filter(muestra == 'entrena')
df_pr <- df %>% filter(muestra == 'prueba')
df_ent <- sample_n(df_ent, nrow(df_ent)) #permutamos al azar
df_ent_grande <- df_ent
df_ent <- df_ent %>% sample_n(700)Intentemos algo simple para empezar: consideramos qué palabras contiene cada reseña, e intentamos clasificar en base esas palabras. Así que en primer lugar dividimos cada texto en tokens (pueden ser palabras, o sucesiones de caracteres o de palabras de tamaño fijo (n-gramas), oraciones, etc.). En este caso, usamos el paquete tidytext. La función unnest_tokens elimina signos de puntuación, convierte todo a minúsculas, y separa las palabras:
Vamos a calcular los tokens y ordernarlos por frecuencia. Empezamos calculando nuestro vocabulario. Supongamos que usamos las 50 palabras más comunes, y usamos poca regularización:
vocabulario <- calc_vocabulario(df_ent, 50)
head(vocabulario)## # A tibble: 6 x 2
## palabra frec
## <chr> <int>
## 1 a 12904
## 2 about 1228
## 3 all 1464
## 4 an 2000
## 5 and 12173
## 6 are 2359tail(vocabulario)## # A tibble: 6 x 2
## palabra frec
## <chr> <int>
## 1 what 1006
## 2 when 1091
## 3 which 1153
## 4 who 1870
## 5 with 3705
## 6 you 1565- Todas las etapas de preprocesamiento deben hacerse en función de los datos de entrenamiento. En este ejemplo, podríamos cometer el error de usar todos los datos para calcular el vocabulario.
- Nuestras entradas aquí no se ven muy buenas: los términos más comunes son en su mayoría palabras sin significado, de modo que no esperamos un desempeño muy bueno. En este momento no nos preocupamos mucho por eso, queremos correr los primeros modelos.
library(glmnet)
mod_x <- correr_modelo(df_ent, df_pr, vocabulario, lambda = 1e-1)## [1] "Tokenizar"
## [1] "Construir matrices X, y"
## [1] "Ajustar modelo"
## [1] "Evaluar modelo"
## [1] "Error entrenamiento: 0.31"
## [1] "Error prueba: 0.36"
## [1] "Devianza entrena:1.148"
## [1] "Devianza prueba:1.271"10.4 Diagnósticos: sesgo y varianza
Y notamos que
- El error de entrenamiento no es satisfactorio: está muy por arriba de nuestro objetivo (10%)
- Hay algo de brecha entre entrenamiento y prueba, de modo que disminuir varianza puede ayudar.
¿Qué hacer? Nuestro clasificador ni siquiera puede clasificar bien la muestra de entrenamiento, lo que implica que nuestro modelo tiene sesgo alto. Controlar la varianza no nos va a ayudar a resolver nuestro problema en este punto. Podemos intentar un modelo más flexible.
Para disminuir el sesgo podemos:
- Expander el vocabulario (agregar más entradas)
- Crear nuevas entradas a partir de los datos (más informativas)
- Usar un método más flexible (como redes neuronales)
- Regularizar menos
Cosas que no van a funcionar (puede bajar un poco el error de validación, pero el error de entrenamiento es muy alto):
- Conseguir más datos de entrenamiento (el error de entrenamiento va a subir, y el de validación va a quedar muy arriba, aunque disminuya)
- Regularizar más (misma razón)
- Usar un vocabulario más chico, eliminar entradas (misma razón)
Por ejemplo, si juntáramos más datos de entrenamiento (con el costo que esto implica), obtendríamos:
mod_x <- correr_modelo(df_ent_grande, df_pr, vocabulario, lambda = 1e-1)## [1] "Tokenizar"## Joining, by = "palabra"
## Joining, by = "palabra"## [1] "Construir matrices X, y"
## [1] "Ajustar modelo"
## [1] "Evaluar modelo"
## [1] "Error entrenamiento: 0.31"
## [1] "Error prueba: 0.35"
## [1] "Devianza entrena:1.187"
## [1] "Devianza prueba:1.246"Vemos que aunque bajó ligeramente el error de prueba, el error es demasiado alto. Esta estrategia no funcionó con este modelo, y hubiéramos perdido tiempo y dinero (por duplicar el tamaño de muestra) sin obtener mejoras apreciables.
Observación: el error de entrenamiento subió. ¿Puedes explicar eso? Esto sucede porque típicamente el error para cada caso individual de la muestra original sube, pues la optimización se hace sobre más casos. Es más difícil ajustar los datos de entrenamiento cuando tenemos más datos.
En lugar de eso, podemos comenzar quitando regularización, por ejemplo
mod_x <- correr_modelo(df_ent, df_pr, vocabulario, lambda =1e-10)## [1] "Tokenizar"## Joining, by = "palabra"
## Joining, by = "palabra"## [1] "Construir matrices X, y"
## [1] "Ajustar modelo"
## [1] "Evaluar modelo"
## [1] "Error entrenamiento: 0.29"
## [1] "Error prueba: 0.37"
## [1] "Devianza entrena:1.099"
## [1] "Devianza prueba:1.32"Y notamos que reducimos un poco el sesgo. Por el momento, seguiremos intentando reducir sesgo. Podemos ahora incluir más variables
vocabulario <- calc_vocabulario(df_ent, 3000)
mod_x <- correr_modelo(df_ent, df_pr, vocabulario, lambda=1e-10)## [1] "Tokenizar"## Joining, by = "palabra"
## Joining, by = "palabra"## [1] "Construir matrices X, y"
## [1] "Ajustar modelo"
## [1] "Evaluar modelo"
## [1] "Error entrenamiento: 0"
## [1] "Error prueba: 0.38"
## [1] "Devianza entrena:0"
## [1] "Devianza prueba:7.66"El sesgo ya no parece ser un problema: Ahora tenemos un problema de varianza.
Podemos regularizar más:
mod_x <- correr_modelo(df_ent, df_pr, vocabulario, lambda=1e-6)## [1] "Tokenizar"## Joining, by = "palabra"
## Joining, by = "palabra"## [1] "Construir matrices X, y"
## [1] "Ajustar modelo"
## [1] "Evaluar modelo"
## [1] "Error entrenamiento: 0"
## [1] "Error prueba: 0.3"
## [1] "Devianza entrena:0"
## [1] "Devianza prueba:3.203"mod_x <- correr_modelo(df_ent, df_pr, vocabulario, lambda=0.05)## [1] "Tokenizar"## Joining, by = "palabra"
## Joining, by = "palabra"## [1] "Construir matrices X, y"
## [1] "Ajustar modelo"
## [1] "Evaluar modelo"
## [1] "Error entrenamiento: 0"
## [1] "Error prueba: 0.18"
## [1] "Devianza entrena:0.072"
## [1] "Devianza prueba:0.764"10.5 Refinando el pipeline
El error de entrenamiento es satisfactorio todavía, y nos estamos acercando a nuestro objetivo (intenta regularizar más para verificar que el problema ahora es sesgo). En este punto, podemos intentar reducir varianza (reducir error de prueba con algún incremento en error de entrenamiento).
- Buscar más casos de entrenamiento: si son baratos, esto podría ayudar (aumentar al doble o 10 veces más).
- Redefinir entradas más informativas, para reducir el número de variables pero al mismo tiempo no aumentar el sesgo.
Intentaremos por el momento el segundo camino (reducción de varianza). Podemos intentar tres cosas:
- Eliminar los términos que son demasiado frecuentes (son palabras no informativas, como the, a, he, she, etc.). Esto podría reducir varianza sin afectar mucho el sesgo.
- Usar raíces de palabras en lugar de palabras (por ejemplo, transfomar defect, defects, defective -> defect y boring,bored, bore -> bore, etc.). De esta manera, controlamos la proliferación de entradas que indican lo mismo y aumentan varianza - y quizá el sesgo no aumente mucho.
- Intentar usar bigramas - esto reduce el sesgo, pero quizá la varianza no aumente mucho.
data("stop_words")
head(stop_words)## # A tibble: 6 x 2
## word lexicon
## <chr> <chr>
## 1 a SMART
## 2 a's SMART
## 3 able SMART
## 4 about SMART
## 5 above SMART
## 6 according SMARThead(calc_vocabulario(df_ent, 100))## # A tibble: 6 x 2
## palabra frec
## <chr> <int>
## 1 a 12904
## 2 about 1228
## 3 after 569
## 4 all 1464
## 5 also 704
## 6 an 2000head(calc_vocabulario(df_ent, 100, remove_stop = TRUE))## # A tibble: 6 x 2
## palabra frec
## <chr> <int>
## 1 2 179
## 2 acting 224
## 3 action 418
## 4 actor 165
## 5 actors 256
## 6 american 193vocabulario <- calc_vocabulario(df_ent, 2000, remove_stop = TRUE)
head(vocabulario %>% arrange(desc(frec)),20)## # A tibble: 20 x 2
## palabra frec
## <chr> <int>
## 1 film 2991
## 2 movie 1844
## 3 time 797
## 4 review 788
## 5 story 749
## 6 character 639
## 7 characters 631
## 8 life 527
## 9 films 515
## 10 plot 490
## 11 bad 484
## 12 people 484
## 13 scene 482
## 14 movies 455
## 15 scenes 443
## 16 action 418
## 17 director 413
## 18 love 393
## 19 real 329
## 20 world 323tail(vocabulario %>% arrange(desc(frec)),20)## # A tibble: 20 x 2
## palabra frec
## <chr> <int>
## 1 shock 18
## 2 sir 18
## 3 sleep 18
## 4 sole 18
## 5 spot 18
## 6 stays 18
## 7 stereotypical 18
## 8 strip 18
## 9 supergirl 18
## 10 taylor 18
## 11 threat 18
## 12 thrillers 18
## 13 tradition 18
## 14 tree 18
## 15 trial 18
## 16 trio 18
## 17 triumph 18
## 18 visit 18
## 19 warning 18
## 20 werewolf 18Este vocabulario parece que puede ser más útil. Vamos a tener que ajustar la regularización de nuevo (y también el número de entradas). Nota: este proceso también lo podemos hacer con cv.glmnet de manera más rápida.
require(doMC)## Loading required package: doMC## Loading required package: iterators## Loading required package: parallelregisterDoMC(cores=4)
if(!usar_cache){
mod_x <- correr_modelo_cv(df_ent, df_pr, vocabulario,
lambda = exp(seq(-10,5,0.1)))
saveRDS(mod_x, file = './cache_obj/mod_sentiment_1.rds')
} else {
mod_x <- readRDS('./cache_obj/mod_sentiment_1.rds')
describir_modelo_cv(mod_x)
}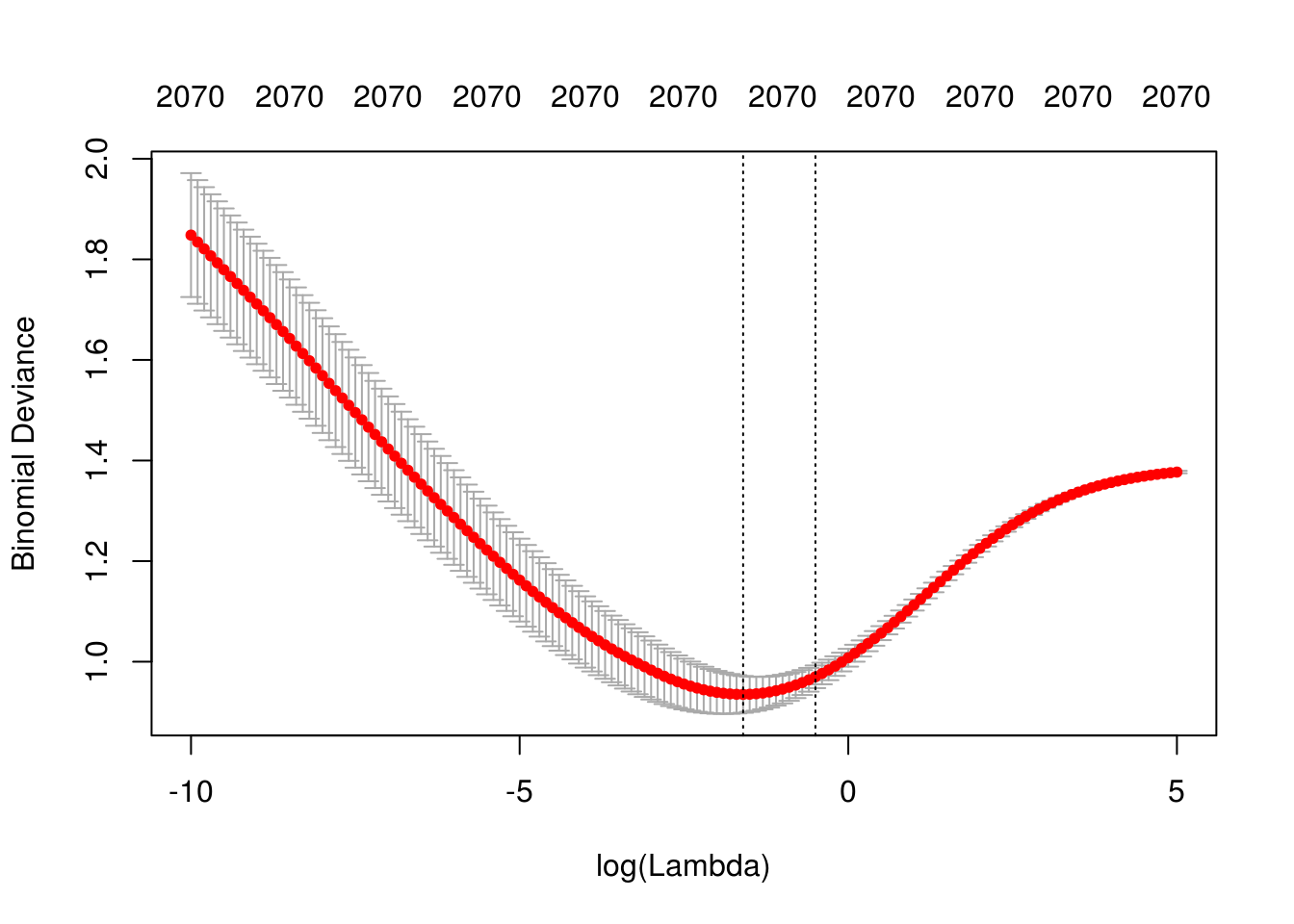
## [1] "Lambda min: 0.201896517994655"
## [1] "Error entrenamiento: 0"
## [1] "Error prueba: 0.21"
## [1] "Devianza entrena:0.261"
## [1] "Devianza prueba:0.879"#mod_x <- correr_modelo(df_ent, df_pr, vocabulario, lambda =1)
#mod_x <- correr_modelo(df_ent, df_pr, vocabulario, lambda =0.1)
#mod_x <- correr_modelo(df_ent, df_pr, vocabulario, lambda =0.01)No estamos mejorando. Podemos intentar con un número diferente de entradas:
vocabulario <- calc_vocabulario(df_ent, 4000, remove_stop = TRUE)
if(!usar_cache){
mod_x <- correr_modelo_cv(df_ent, df_pr, vocabulario, lambda = exp(seq(-10,5,0.1)))
saveRDS(mod_x, file = './cache_obj/mod_sentiment_2.rds')
} else {
mod_x <- readRDS('./cache_obj/mod_sentiment_2.rds')
describir_modelo_cv(mod_x)
}
## [1] "Lambda min: 0.49658530379141"
## [1] "Error entrenamiento: 0"
## [1] "Error prueba: 0.18"
## [1] "Devianza entrena:0.295"
## [1] "Devianza prueba:0.883"Y parece que nuestra estrategia no está funcionando muy bien. Regresamos a nuestro modelo con ridge
vocabulario <- calc_vocabulario(df_ent, 3000, remove_stop = FALSE)
if(!usar_cache){
mod_x <- correr_modelo_cv(df_ent, df_pr, vocabulario, lambda = exp(seq(-5,2,0.1)))
saveRDS(mod_x, file = './cache_obj/mod_sentiment_3.rds')
} else {
mod_x <- readRDS('./cache_obj/mod_sentiment_3.rds')
describir_modelo_cv(mod_x)
}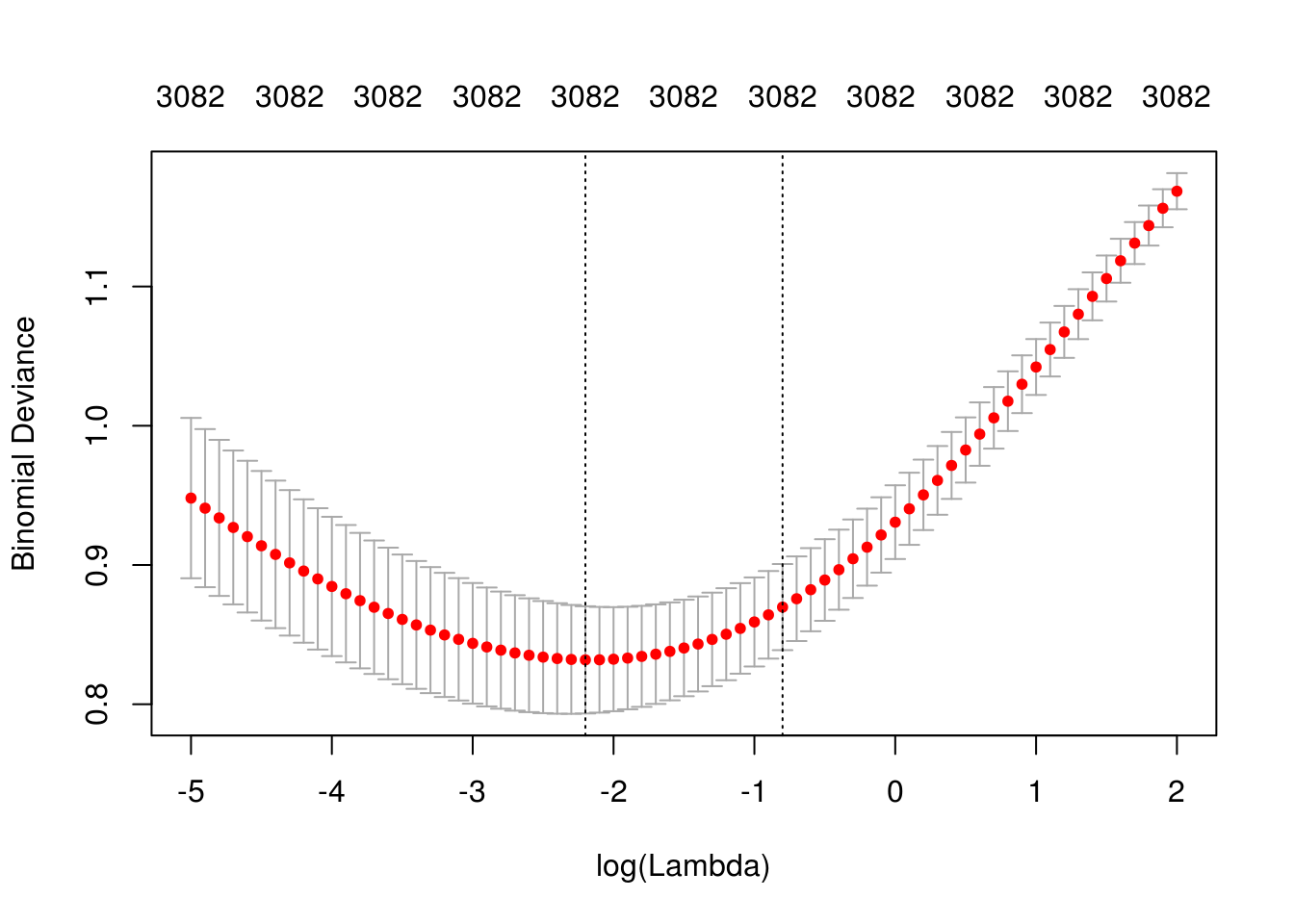
## [1] "Lambda min: 0.110803158362334"
## [1] "Error entrenamiento: 0"
## [1] "Error prueba: 0.18"
## [1] "Devianza entrena:0.128"
## [1] "Devianza prueba:0.775"Podemos intentar aumentar el número de palabras y aumentar también la regularización
vocabulario <- calc_vocabulario(df_ent, 4000, remove_stop = FALSE)
if(!usar_cache){
mod_x <- correr_modelo_cv(df_ent, df_pr, vocabulario, lambda = exp(seq(-5,2,0.1)))
saveRDS(mod_x, file = './cache_obj/mod_sentiment_4.rds')
} else {
mod_x <- readRDS('./cache_obj/mod_sentiment_4.rds')
describir_modelo_cv(mod_x)
}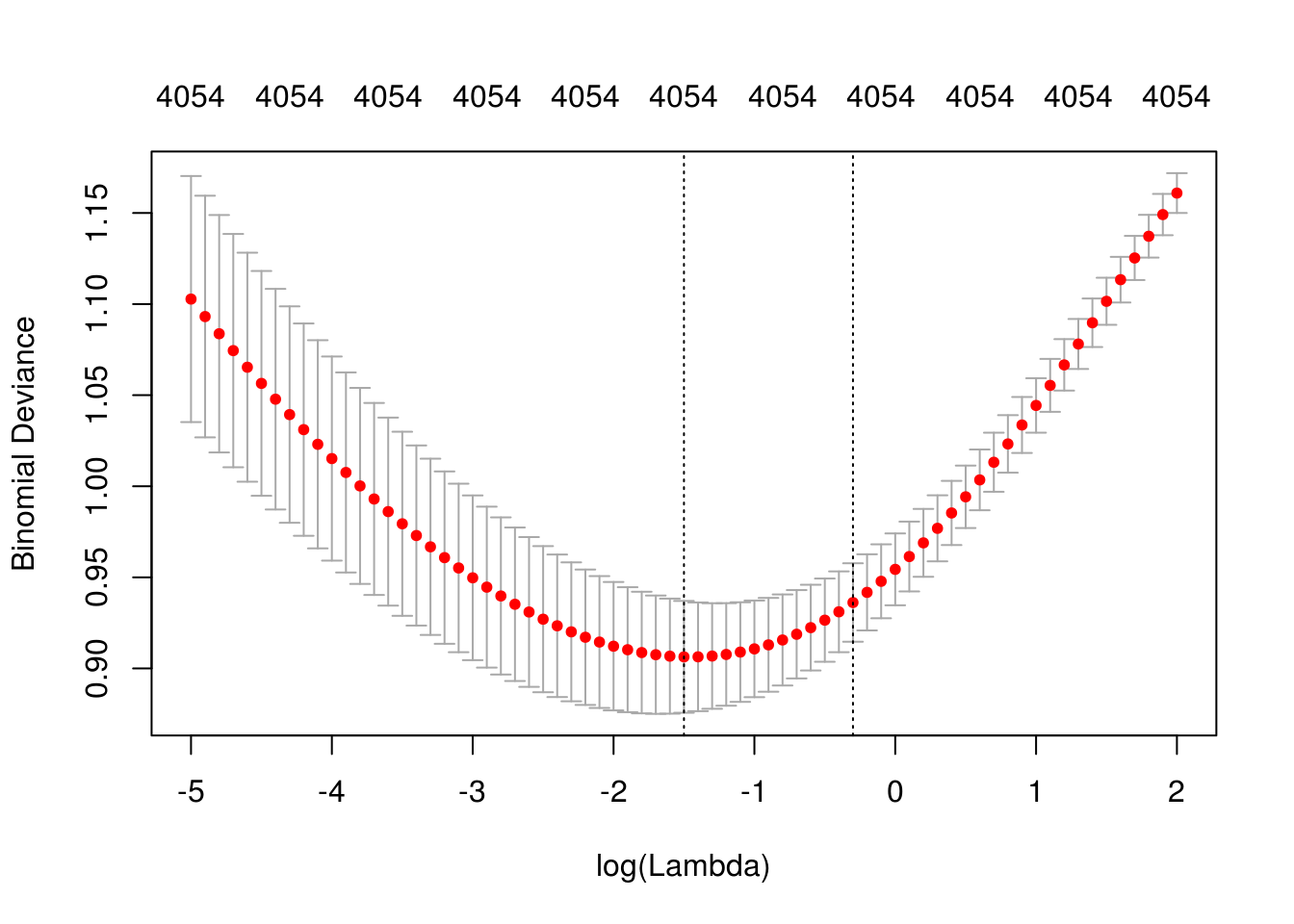
## [1] "Lambda min: 0.22313016014843"
## [1] "Error entrenamiento: 0"
## [1] "Error prueba: 0.16"
## [1] "Devianza entrena:0.173"
## [1] "Devianza prueba:0.776"10.6 Consiguiendo más datos
Como nuestro principal problema es varianza, podemos mejorar buscando más datos. Supongamos que hacemos eso en este caso, conseguimos el doble casos de entrenamiento. En este ejemplo, podríamos etiquetar más reviews: esto es relativamente barato y rápido
vocabulario <- calc_vocabulario(df_ent_grande, 3000, remove_stop = FALSE)
if(!usar_cache){
mod_x <- correr_modelo_cv(df_ent_grande, df_pr, vocabulario, lambda = exp(seq(-5,2,0.1)))
saveRDS(mod_x, file = './cache_obj/mod_sentiment_5.rds')
} else {
mod_x <- readRDS('./cache_obj/mod_sentiment_5.rds')
describir_modelo_cv(mod_x)
}
## [1] "Lambda min: 0.0907179532894125"
## [1] "Error entrenamiento: 0"
## [1] "Error prueba: 0.12"
## [1] "Devianza entrena:0.18"
## [1] "Devianza prueba:0.653"Y ya casi logramos nuestro objetivo. Podemos intentar con más palabras
vocabulario <- calc_vocabulario(df_ent_grande, 4000, remove_stop = FALSE)
if(!usar_cache){
mod_x <- correr_modelo_cv(df_ent_grande, df_pr, vocabulario, lambda = exp(seq(-5,2,0.1)))
saveRDS(mod_x, file = './cache_obj/mod_sentiment_6.rds')
} else {
mod_x <- readRDS('./cache_obj/mod_sentiment_6.rds')
describir_modelo_cv(mod_x)
}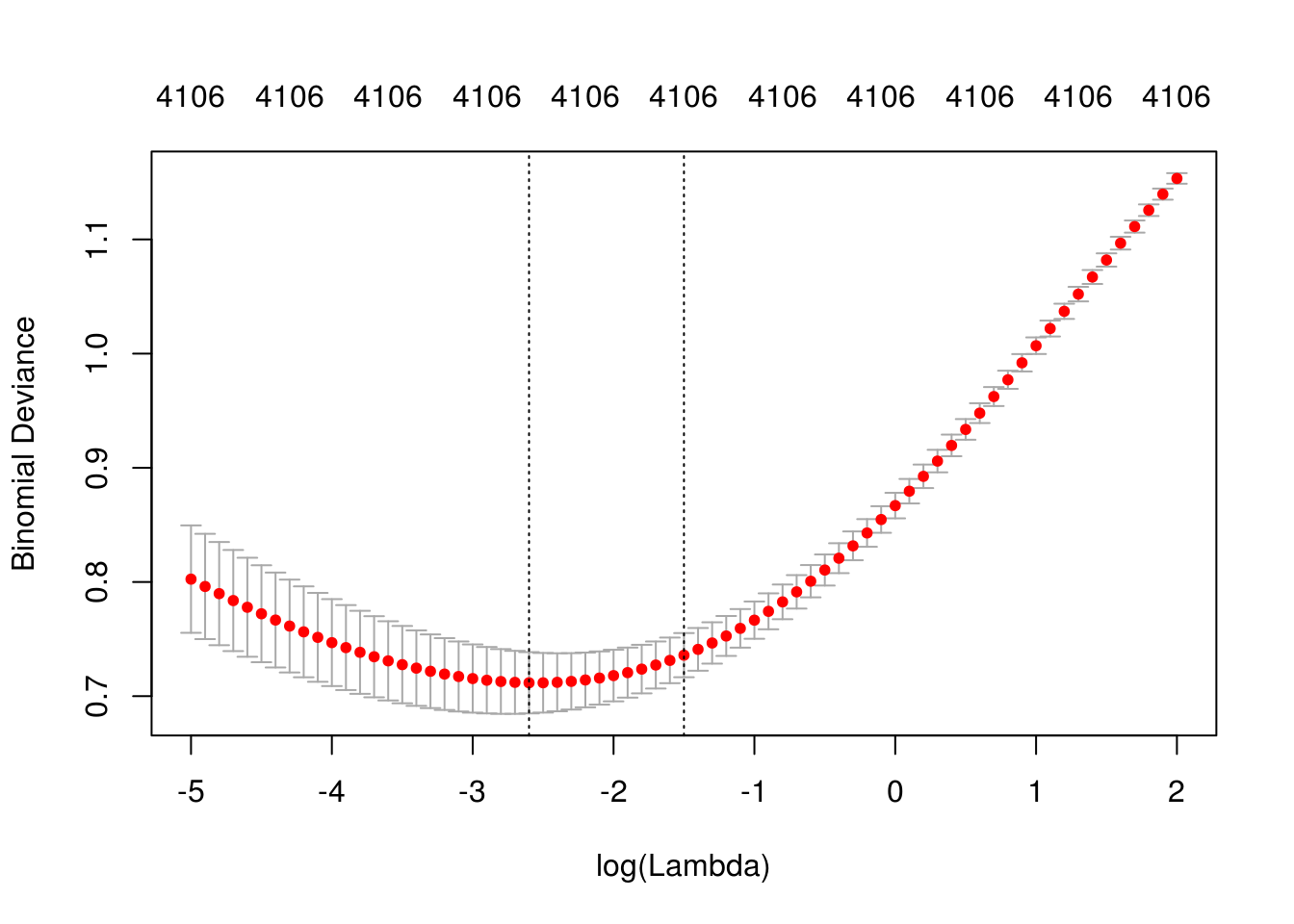
## [1] "Lambda min: 0.0742735782143339"
## [1] "Error entrenamiento: 0"
## [1] "Error prueba: 0.12"
## [1] "Devianza entrena:0.127"
## [1] "Devianza prueba:0.621"Y esto funcionó bien. Subir más la regularización no ayuda mucho (pruébalo). Parece que el sesgo lo podemos hacer chico (reducir el error de entrenamiento considerablemente), pero tenemos un problema más grande con la varianza.
- Quizá muchas palabras que estamos usando no tienen qué ver con la calidad de positivo/negativo, y eso induce varianza.
- Estos modelos no utilizan la estructura que hay en las reseñas, simplemente cuentan qué palabras aparecen. Quizá aprovechar esta estructura podemos incluir variables más informativas que induzcan menos varianza sin aumentar el sesgo.
- Podemos conseguir más datos.
Obsérvese que:
- ¿Podríamos intentar con una red neuronal totalmente conexa? Probablemente esto no va a ayudar, pues es un modelo más complejo y nuestro problema es varianza.
10.7 Usar datos adicionales
Intentemos el primer camino. Probamos usar palabras que tengan afinidad como parte de su significado (positivas y negativas). Estos datos están incluidos en el paquete tidytext.
bing <- filter(sentiments, lexicon == 'bing')
tail(bing)## # A tibble: 6 x 4
## word sentiment lexicon score
## <chr> <chr> <chr> <int>
## 1 zealous negative bing NA
## 2 zealously negative bing NA
## 3 zenith positive bing NA
## 4 zest positive bing NA
## 5 zippy positive bing NA
## 6 zombie negative bing NAdim(vocabulario)## [1] 4106 2vocabulario <- calc_vocabulario(df_ent_grande, 8000, remove_stop = FALSE)
voc_bing <- vocabulario %>% inner_join(bing %>% rename(palabra = word))## Joining, by = "palabra"dim(voc_bing)## [1] 1476 5mod_x <- correr_modelo_cv(df_ent_grande, df_pr, voc_bing, alpha=0,
lambda = exp(seq(-5,2,0.1)))## Joining, by = "palabra"
## Joining, by = "palabra"describir_modelo_cv(mod_x)
## [1] "Lambda min: 0.122456428252982"
## [1] "Error entrenamiento: 0.02"
## [1] "Error prueba: 0.17"
## [1] "Devianza entrena:0.381"
## [1] "Devianza prueba:0.774"Estas variables solas no dan un resultado tan bueno (tenemos tanto sesgo como varianza altas). Podemos combinar:
vocabulario <- calc_vocabulario(df_ent_grande, 3000, remove_stop =FALSE)
voc <- bind_rows(vocabulario, voc_bing %>% select(palabra, frec)) %>% unique
dim(voc)## [1] 4021 2mod_x <- correr_modelo_cv(df_ent_grande, df_pr, voc, alpha=0, lambda = exp(seq(-5,2,0.1)))## Joining, by = "palabra"
## Joining, by = "palabra"describir_modelo_cv(mod_x)
## [1] "Lambda min: 0.0907179532894125"
## [1] "Error entrenamiento: 0"
## [1] "Error prueba: 0.13"
## [1] "Devianza entrena:0.147"
## [1] "Devianza prueba:0.633"Este camino no se ve mal, pero no hemos logrado mejoras. Aunque quizá valdría la pena intentar refinar más y ver qué pasa.
10.8 Examen de modelo y Análisis de errores
Ahora podemos ver qué errores estamos cometiendo, y cómo está funcionando el modelo. Busquemos los peores. Corremos el mejor modelo hasta ahora:
vocabulario <- calc_vocabulario(df_ent_grande, 4000, remove_stop = FALSE)
mod_x <- correr_modelo_cv(df_ent_grande, df_pr, vocabulario, lambda = exp(seq(-5,2,0.1)))## Joining, by = "palabra"
## Joining, by = "palabra"describir_modelo_cv(mod_x)
## [1] "Lambda min: 0.0820849986238988"
## [1] "Error entrenamiento: 0"
## [1] "Error prueba: 0.12"
## [1] "Devianza entrena:0.136"
## [1] "Devianza prueba:0.623"coeficientes <- predict(mod_x$mod, lambda = 'lambda.min', type = 'coefficients')
coef_df <- data_frame(palabra = rownames(coeficientes),
coef = coeficientes[,1])
arrange(coef_df, coef) %>% print(n=20)## # A tibble: 4,107 x 2
## palabra coef
## <chr> <dbl>
## 1 (Intercept) -0.510
## 2 sloppy -0.305
## 3 tiresome -0.304
## 4 tedious -0.300
## 5 designed -0.275
## 6 forgot -0.275
## 7 profanity -0.274
## 8 insulting -0.264
## 9 redeeming -0.258
## 10 ludicrous -0.257
## 11 asleep -0.253
## 12 embarrassing -0.250
## 13 miserably -0.244
## 14 alas -0.243
## 15 lifeless -0.238
## 16 random -0.234
## 17 abilities -0.228
## 18 inept -0.227
## 19 ridiculous -0.227
## 20 stupidity -0.223
## # ... with 4,087 more rowsarrange(coef_df, desc(coef)) %>% print(n=20)## # A tibble: 4,107 x 2
## palabra coef
## <chr> <dbl>
## 1 refreshing 0.293
## 2 beings 0.275
## 3 underneath 0.275
## 4 commanding 0.250
## 5 outstanding 0.237
## 6 marvelous 0.227
## 7 finest 0.223
## 8 identify 0.220
## 9 enjoyment 0.218
## 10 ralph 0.213
## 11 exceptional 0.212
## 12 anger 0.208
## 13 mature 0.208
## 14 threatens 0.208
## 15 luckily 0.205
## 16 enters 0.205
## 17 overall 0.201
## 18 breathtaking 0.200
## 19 popcorn 0.199
## 20 portrait 0.196
## # ... with 4,087 more rowsY busquemos las diferencias más grandes del la probabilidad ajustada con la clase observada
y <- mod_x$prueba$y
x <- mod_x$prueba$x
probs <- predict(mod_x$mod, newx = x, type ='response', s='lambda.min')
df_1 <- data_frame(id = rownames(x), y=y, prob = probs[,1]) %>%
mutate(error = y - prob) %>% arrange(desc(abs(error)))
df_1## # A tibble: 425 x 4
## id y prob error
## <chr> <dbl> <dbl> <dbl>
## 1 1508 1 0.0408 0.959
## 2 1461 1 0.0490 0.951
## 3 1490 1 0.0949 0.905
## 4 1933 1 0.110 0.890
## 5 222 0 0.889 -0.889
## 6 25 0 0.859 -0.859
## 7 1642 1 0.143 0.857
## 8 728 0 0.851 -0.851
## 9 1050 1 0.152 0.848
## 10 415 0 0.844 -0.844
## # ... with 415 more rowsfilter(df, id == 1461) %>% pull(texto)[1] “Review deep rising is one of " those " movies . the kind of movie which serves no purpose except to entertain us . it does not ask us to think about important questions like life on other planets or the possibility that there is no god . . . screw that , it says boldly , let’s see some computer generated monsters rip into , decapitate and generally cause irreparable booboos to a bunch of little known actors . heh ! them wacky monsters , gotta love ’em . of course , since we can rent about a thousand b movies with the same kind of story , hollywood must give that little extra " oumph " to get people in theaters . that is where deep rising fails , which is a good thing . confused ? let me explain : despite all them flashy effects and big explosions , deep rising is still , at heart , a good ’ol b movie . luckily , it’s a very good b movie . the worst cliches in movie history are a b movie’s bread and butter . therefore , things that would destroy a serious movie actually help us have a good time while watching a movie of lower calibre . of course we know there’s a big slimy creature behind that door , that one person will wander off to be picked off by said monster and we always know which persons or person will make it out alive . we just don’t know when or how horrible it will be . i went to see deep rising with my expections low and my tolerance for bad dialogue high . imagine my surprise when i discover that deep rising is actually , well , pretty darn funny at times . a funny b movie ? well , that’s new . these flicks are not supposed to make us laugh . ( except for a few unintended laughs once a while . ) and before you know it , treat williams , wes studi and famke jansen appear on the big screen . hey ! i know them guys ( and gal ) from a couple of other movies . cool . familiar faces . so far so good . our man treat is the hero , he’ll live . wes is a staple of b movies , he is the token victim . we know he’ll buy the farm but he will take a few creeps with him on the way out . famke is the babe , ’nuff said . there is also a guy with glasses ( the guy with glasses always dies ) a black person ( b movie buffs know that the black guy always dies , never fails ) and a very funny , nerdy guy . ( ah ! comic relief . how can we possibly explain having to kill him . . . let him live . ) after the first fifteen minutes i felt right at home . i know who to root for and who i need to boo too and a gum to chew . ( please kill me . ) suffice it to say that for the next hour and a half i jumped out of my seat a few times , went " ewwww " about a dozen times and nearly had an orgasm over all the explosions and firepower our heroes were packing . i’m a man , we nottice these things . all in all , i’d recommend deep rising if you are looking for a good time and care to leave your brain at the door . . . but bring your sense of humor and excitement in with you . the acting is decent , the effects top rate . how to best describe it ? put together the jet ski scene from hard rain , the bug attacks from starship troopers , a couple of james bond like stunts and all those scenes from friday the thirteenth and freddy where you keep screaming " don’t go there , he’s behind you " and you end up with deep rising . for creepy crawly goodness , tight t-shirts , major firepower and the need to go to the bathroom every fifteen minutes from seing all that water .”
filter(df, id == 1508) %>% pull(texto)[1] “Review capsule : side-splitting comedy that follows its own merciless logic almost through to the end . . . but not without providing a good deal of genuine laughs . most comedies these days have one flaw . they’re not funny . they think they’re funny , but they are devoid of anything really penetrating or dastardly . occasionally a good funny movie sneaks past the deadening hollywood preconceptions of humor and we get a real gem : ruthless people , for instance , which established a microcosm of a setup and played it out to the bitter end . liar liar is built the same way and is just about as funny . this is one of the few movies i’ve seen where i was laughing consistently almost all the way through : instead of a couple of set-pieces that inspired a laugh ( think of the dismal fatal instinct ) , the whole movie works like clockwork . jim carrey playes a high-powered lawyer , to whom lying is as natural as breathing . there is one thing he takes seriously , though : his son , and we can sense the affection that they have for each other right away . but his wife is divorced and seeing another man , and now it looks like they may move away together . the son goes with them , of course . the movie sets up this early material with good timing and a remarkable balance of jim carrey’s over-the-top persona with reality . then the plot springs into action : after being snubbed ( not deliberately ) by his father at his birthday , the kid makes a wish as he blows out the birthday candles : that for just one day , dad can’t lie . he gets the wish . what happens next is sidesplitting . everything turns into a confrontation : when cornered by a bum for some change , he shouts , " no ! i’m not giving you any money because i know you’ll spend it on booze ! all i want to do is to get to the office without having to step over the debris of our decaying society ! " he can’t even get into an elevator without earning a black eye . and what’s worse , he’s now gotten himself into an expensive divorce settlement that requires him to twist the truth like abstract wire sculpture . carrey , who i used to find unfunny , has gotten better at his schtick , even if it’s a limited one . he uses it to great effect in this movie . there is a scene where he tries to test his ability to lie and nearly demolishes his office in the process ( there’s a grin breaking out across my face right now , just remembering the scene ) . he can’t even write the lie ; his fingers twitch , his body buckles like someone in the throes of cyanide poisoning , and when he tries to talk it’s like he’s speaking in tongues . equally funny is a scene where he beats himself to a pulp ( don’t ask why ) , tries to drink water to keep from having outbursts in the courtroom ( it fails , with semi-predictable results ) , and winds up biting the bullet when he gets called into the boardroom to have everyone ask what they think of them . this scene alone may force people to stop the tape for minutes on end . the movie sustains its laughs and also its flashes of insight until almost the end . a shame , too , because the movie insists on having a big , ridiculous climax that involves carrey’s character flagging down a plane using a set of motorized stairs , then breaking his leg , etc . a simple reconciliation would do the trick . why is this stupid pent-up climax always obligatory ? it’s not even part of the movie’s real agenda . thankfully , liar liar survives it , and so does carrey . maybe they were being merciful , on reflection . if i’d laughed any more , i might have needed an iron lung .”
filter(df, id == 222) %>% pull(texto) #negativa[1] “Review it’s probably inevitable that the popular virtual reality genre ( " the matrix , " " existenz " ) would collide with the even more popular serial-killer genre ( " kiss the girls , " " se7en " ) . the result should have been more interesting than " the cell . " as the movie opens , therapist catharine deane ( jennifer lopez ) treats a catatonic boy ( colton james ) by entering his mind through some sort of virtual reality technique that’s never fully explained . after months of therapy sessions in a surreal desert , catharine has no success to report . meanwhile , killer carl stargher ( vincent d’onofrio ) has claimed another victim . his particular hobby is to kidnap young women , keep them in a glass cell overnight , and drown them . he takes the corpse and soaks it in bleach , then suspends himself over the body and jerks off while watching a video tape of the drowning . although carl’s been doing this for awhile , he’s recently become sloppy , and fbi agent peter novak ( vince vaughn ) is closing in fast . not fast enough , though , to keep carl from sticking another woman ( tara subkoff ) in the cell or to catch him before he suffers a schizophrenic attack that leaves him in a coma . from the videos in carl’s house , peter can see that the drowning cell is automated and will fill with water forty hours after the abduction . to save the kidnapped girl , peter has to find the cell before the end of the day , and comatose carl’s not talking . so off they go to catharine in the hope that she can go inside carl’s mind and find out where the cell is in time . the focus of " the cell " in on the ornate interior of carl’s mind , but the universe director tarsem singh creates seems more an exercise in computer-generated spectacle than an exploration of the psychotic personality . for the most part , it’s style without substance . in his own mind , carl is a decadent emperor in flowing robes , ming the merciless , as well as a frightened boy ( jake thomas ) abused by his father . all in all , the mind of a psycho killer turns out to be a strangely dull place , and i kept wishing i could fast-forward to the next development . singh is best known for directing music videos , particularly rem’s " losing my religion , " and " the cell " seems very much like a really long , really slow mtv video with the sound deleted . singer lopez seems to think she’s in a video as well ; she devotes more time to posing in elaborate costumes than she does to acting . the premise had great promise . the computer-generated world within carl’s mind could have been a bizarre , surreal universe governed by insanity and symbolism rather than logic . the first room catharine enters in carl’s head shows this promise . she finds a horse standing in center of the room ; suddenly , sheets of sharp-edged glass fall into the horse , dividing it into segments . the panes of glass separate , pulling apart the pieces of the still-living horse . this scene is twisted , disturbing , and thought-provoking , because the psychological importance of the horse and its fate is left to the viewer to ponder . another element that should have been developed is the effect on catharine of merging with the mind of a psychopath . their minds begin to bleed together at one point in the movie , and this should have provided an opportunity to discover the dark corners of catharine’s own psyche . like sidney lumet’s " the offence " or michael mann’s " manhunter , " " the cell " could have explored how the madness of the killer brings out a repressed darkness in the investigator . however , catharine’s character is hardly developed at all , and lopez has no depth to offer the role . bottom line : don’t get trapped in this one .”
filter(df, id == 25) %>% pull(texto) #negativa[1] “Review forgive the fevered criticism but the fervor of the crucible infects . set in 1692 at salem , massachusetts , the crucible opens with a group of teenage girls passionately singing and dancing around a boiling cauldron in the middle of a forest under the glow of a full moon . they beckon the names of men as the targets of their love spells . then one of the girls lets her hair down and sheds her clothes . not to be outdone in her quest to regain the attention of john proctor ( daniel day lewis ) , abigail ( winona ryder ) suddenly seizes a chicken , beats it against the ground and smears her face and lips with the fresh blood . taking even adolescent hormone surges into account , surely this chicken-bashing bit is a bit excessive , especially for prim puritan sensibilities ? surely to the puritan eye this is as close to a coven of witches as it gets ? the crucible errs from the beginning and arthur miller’s name should be summoned for blame here for the addition of the above scene to his screen adaptation of his play . this is far from a harmless event , a bad start to an already shaky morality tale . the play describes the film’s opening scene during tense exchanges that makes one wonder about the veracity of both accusation and reply , and this adds to the play’s charged atmosphere . in the film , the opening scene becomes an unintentional pandora’s box . not only is credulity stretched but abigail’s obsession is unfortunately spotlighted . it positions the crucible more as a cautionary fable about obsessive and malevolent women than against witch hunts ; it will bring back the memory of a rabbit boiling away in a pot . not surprisingly , the nighttime forest frenzy does not go unnoticed and when two girls fail to wake the following morning , witches are invoked by those eager to blame . when the girls are questioned , their confession of guilt is accompanied with an announcement of their return to god and they are thereafter converted to immaculate witnesses , led lustfully by abigail . with alarming synchronicity our hormonally-advantaged girls zealously gesture and point accusing fingers at innocents , constant reminders that abigail’s passion sets all this into inexorable motion . abigail seizes on this opportunity to rid herself of her rival for john proctor’s love , his wife elizabeth ( joan allen ) , by including her among those accused of witchcraft . appropriately narrow-waisted and equipped with a distractingly white smile ( watch his teeth deteriorate much too quickly to a murky yellow ) , day lewis plays the dashing moral hero with an over-earnestness that longs to be watched . director nicholas hytner is guilty of encouraging day lewis’ foaming-mouth fervour with shots where we stare up at proctor as if he was mounted on a pedestal for our admiration . otherwise , hytner’s direction is unremarkable . ryder’s performance as abigail is as consistent as her mood swings . her fits of frenzy are energetic enough but the quieter moments are less successful . abigail supposedly revels in her newfound power , but ryder fails at being convincingly haughty although there is much haughtiness to spare here . paul scofield is fine as the overzealous judge danforth , but the incessant moral posturings of all the characters along with the recurrent histrionics of the young girls pricks at the nerves . probably because she is the only refuge of restraint amidst all the huffing and puffing , allen’s elizabeth comes out as the most sympathetic character . a scene near the end featuring a private conversation between the imprisoned elizabeth and john is undeniably powerful because for once we are given a reprieve from the moral bantering and the human consequences are revealed . unfortunately , when john’s audience again increases to more than one his urge to pontificate returns and the human urgency of his situation is lost . it is clear that miller meant well but i do wish he did it with more delicacy and fewer diversions . his screenplay is an imperfect creature with the distractions coming out as loud as the message . the result is a clumsy muddle - i felt like the chicken from the opening scene , head ceaselessly banged with piousness too heavy-handed to be wholly believable . when the gallows beckoned , it was sweet release indeed . far from bewitching , the crucible tests the patience .”
filter(df, id == 728) %>% pull(texto) #negativa[1] “Review girl 6 is , in a word , a mess . i was never able to determine what spike lee was trying to accomplish with this film . there was no sense of where the film was going , or any kind of coherent narrative . if there was a point to the film , i missed it . girl 6 , by the way , is the way theresa randle’s character is addressed in the phone sex workplace ; all the girls are known by their numbers . the plot , such as it is : theresa randle is a struggling n . y . actress , and eventually takes a job as a phone-sex operator . she begins to lose contact with reality , as her job consumes her . also , she must deal with the advances of her ex-husband ( isiah washington ) . he is an ex- con thief , and she tries to keep him away , while at the same time , it’s clear that she still harbors feelings for him . her neighbor , jimmy ( spike lee ) functions as the observer ; mediating between the ex- husband and girl 6 . he also functions as a point of stability , as he watches her become seduced by the lurid world of phone sex . the soundtrack , consisting of songs by prince , was jarring . it kept taking my attention from the film - not altogether a bad thing , i’ll grant you , as what was transpiring onscreen wasn’t that riveting . for parts of the middle of the film , the music stayed blissfully in the background . in the opening sequence and one scene later in the film , however , the music was particularly loud and distracting . of course , i’ve never really cared for prince’s ( or tafkap if you like ) music . prince fans might love the soundtrack , but it will probably be distracting , even to die-hard fans . of the performances , the only one that stood out was spike lee’s buddy character , jimmy . he was excellent as the always-broke neighbor of girl 6 . he should have stuck to acting in this film . there are several sequences that gave me the impression that he’d like to be oliver stone when he grows up . there are scenes shot with different types of film , which are purposely grainy , and reminiscent of some of the scenes in oliver stone’s natural born killers . in that film , they worked to propel the narrative . in this film , they just made me more confused . there are some amusing moments , and a few insights into the lives of the women who use their voices to make the phone-sex industry the multi-billion dollar industry that it has become . other than that , though , nothing much happens . there are a few intense moments , as when one caller becomes frightening , but even that is rather lackluster . i’m not the biggest fan of spike lee , though i’d agree that he has done some very good work in the past . in girl 6 , though , he seems to be floundering . he had an interesting idea , a fairly good setup , and seemed to wander aimlessly from there . girl 6 earns a grade of d .”
Algunos de los errores son difíciles (por ejemplo, una reseña que dice que la película es tan mala que es buena). Otros quizá podemos hacer algo con nuestro método: en algunas partes vemos algunas problemas con nuestro método, por ejemplo, “no energy” - nuestro método no toma en cuenta el orden de las palabras. Podemos intentar capturar algo de esto usando bigramas (pares de palabras) en lugar de simplemente usar palabras.
vocabulario <- calc_vocabulario(df_ent_grande, 3800, remove_stop = FALSE)
mod_x <- correr_modelo_cv(df_ent_grande, df_pr, vocabulario, lambda = exp(seq(-5,2,0.1)))## Joining, by = "palabra"
## Joining, by = "palabra"describir_modelo_cv(mod_x)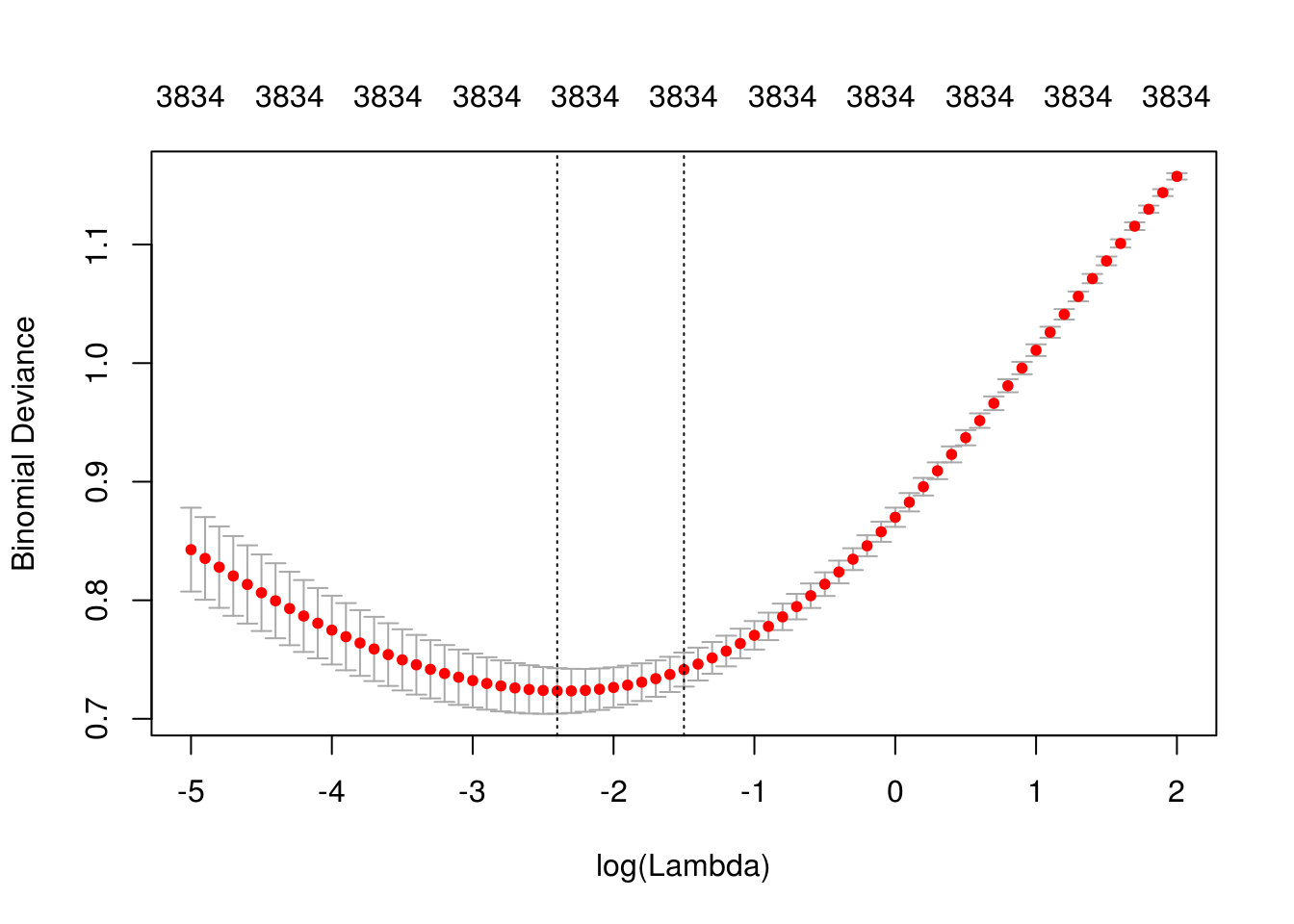
## [1] "Lambda min: 0.0907179532894125"
## [1] "Error entrenamiento: 0"
## [1] "Error prueba: 0.11"
## [1] "Devianza entrena:0.153"
## [1] "Devianza prueba:0.628"vocabulario_bigramas <- calc_vocabulario(df_ent_grande, 500, bigram = TRUE)
vocabulario_bigramas %>% arrange(desc(frec))## # A tibble: 509 x 2
## palabra frec
## <chr> <int>
## 1 of the 6984
## 2 in the 4609
## 3 the film 3167
## 4 is a 2325
## 5 to be 2218
## 6 to the 2187
## 7 and the 2019
## 8 on the 1780
## 9 in a 1756
## 10 the movie 1580
## # ... with 499 more rowsvocabulario_bigramas %>% arrange((frec))## # A tibble: 509 x 2
## palabra frec
## <chr> <int>
## 1 and one 117
## 2 are so 117
## 3 decides to 117
## 4 for some 117
## 5 might have 117
## 6 piece of 117
## 7 sci fi 117
## 8 science fiction 117
## 9 that his 117
## 10 the case 117
## # ... with 499 more rowslibrary(stringr)
mod_bigramas <- correr_modelo_cv(df_ent_grande, df_pr, vocabulario_bigramas,
alpha=1,
lambda = exp(seq(-7,2,0.1)), bigram = TRUE)## Joining, by = "palabra"
## Joining, by = "palabra"describir_modelo_cv(mod_bigramas)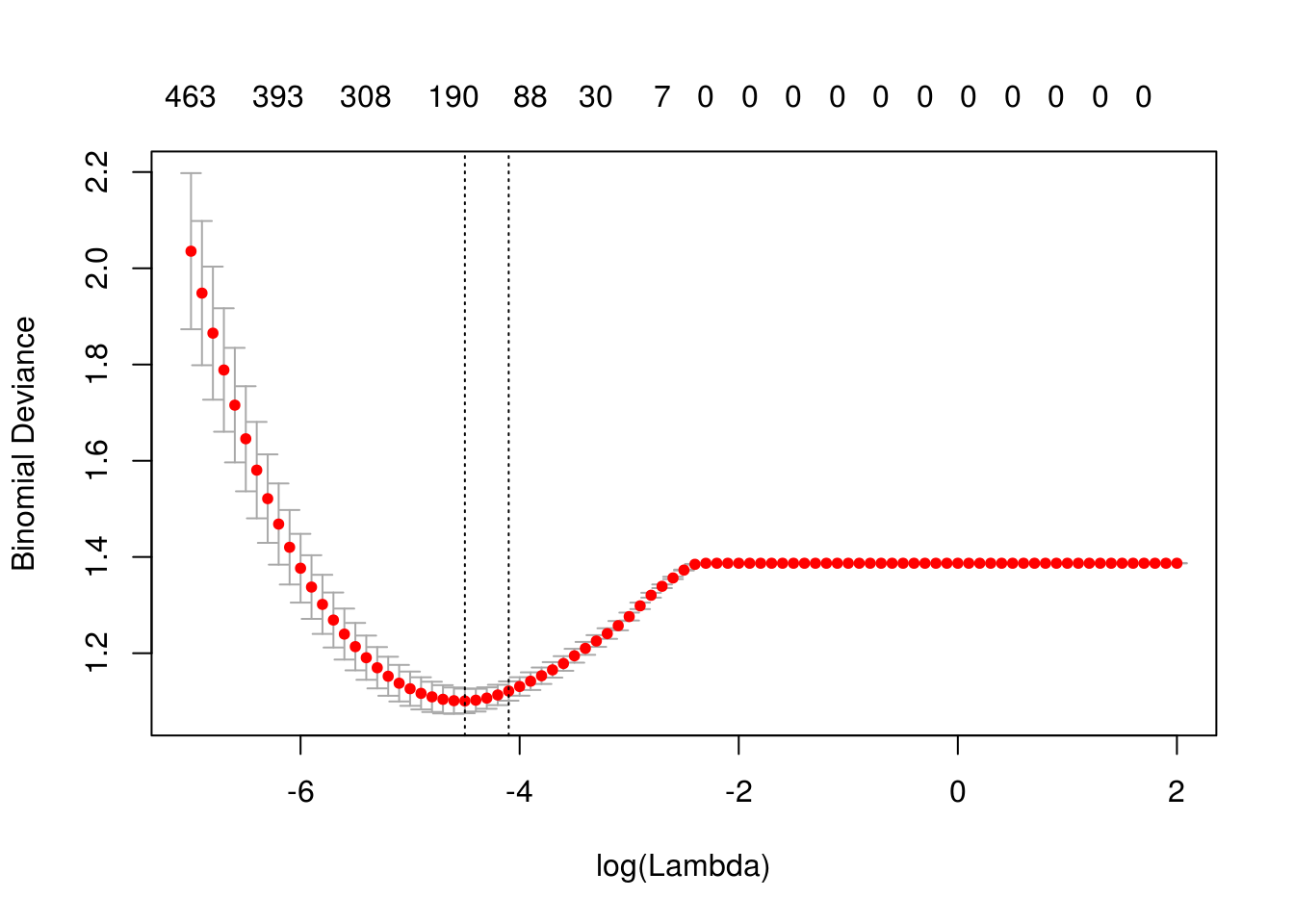
## [1] "Lambda min: 0.0111089965382423"
## [1] "Error entrenamiento: 0.19"
## [1] "Error prueba: 0.28"
## [1] "Devianza entrena:0.892"
## [1] "Devianza prueba:1.078"Este resultado no es tan malo. Podemos intentar construir un modelo juntando unigramas y bigramas:
y <- mod_x$entrena$y
x_1 <- mod_x$entrena$x
x_2 <- mod_bigramas$entrena$x
mod_ub <- cv.glmnet(x = cbind(x_1, x_2),
y = y, alpha = 0.0, family ='binomial',
lambda = exp(seq(-5,1,0.1)))
plot(mod_ub)
x_1p <- mod_x$prueba$x
x_2p <- mod_bigramas$prueba$x
preds_ent <- predict(mod_ub, newx = cbind(x_1,x_2), type='class', lambda ='lambda.min')
mean(preds_ent != mod_x$entrena$y)## [1] 0.0006349206preds_1 <- predict(mod_ub, newx = cbind(x_1p,x_2p), type='class', lambda ='lambda.min')
mean(preds_1 != mod_x$prueba$y)## [1] 0.112941210.8.0.1 Ejemplo (opcional)
En este ejemplo no tenemos muchos datos, pero puedes intentar de todas formas ajustar una red neuronal adaptada al problema (word embeddings, que veremos más adelante, y convoluciones de una dimensión a lo largo de oraciones). Quizá es buena idea empezar con un conjunto de datos más grandes, como dataset_imdb() en el paquete keras.
library(keras)
vocabulario <- calc_vocabulario(df_ent_grande, 2000, remove_stop = FALSE)
dim(vocabulario)
entrena <- convertir_lista(df_ent_grande, vocabulario)
prueba <- convertir_lista(df_pr, vocabulario)
quantile(sapply(entrena$x, length))
x_train <- entrena$x %>%
pad_sequences(maxlen = 2000, truncating="post")
x_test <- prueba$x %>%
pad_sequences(maxlen = 2000, truncating='post')model <- keras_model_sequential()
model %>%
layer_embedding(input_dim = nrow(vocabulario)+1, output_dim = 30,
input_length=2000,
embeddings_regularizer = regularizer_l2(0.01)) %>%
#layer_dropout(0.5) %>%
layer_conv_1d(
filters = 20, kernel_size=3,
padding = "valid", activation = "relu", strides = 1,
kernel_regularizer = regularizer_l2(0.01)) %>%
# layer_dropout(0.5) %>%
layer_global_max_pooling_1d() %>%
layer_dense(20, activation ='relu',
kernel_regularizer = regularizer_l2(0.001)) %>%
#layer_dropout(0.5) %>%
layer_dense(1, activation='sigmoid', kernel_regularizer = regularizer_l2(0.001))
# Compile model
model %>% compile(
loss = "binary_crossentropy",
#optimizer = optimizer_sgd(lr=0.001, momentum=0.0),
optimizer = optimizer_adam(),
metrics = c("accuracy","binary_crossentropy")
)
model %>%
fit(
x_train, entrena$y,
batch_size = 128,
epochs = 200,
# callback = callback_early_stopping(monitor='val_loss', patience=50),
validation_data = list(x_test, prueba$y)
)
print("Entrenamiento")
evaluate(model, x_train, entrena$y)
print("Prueba")
evaluate(model, x_test, prueba$y )