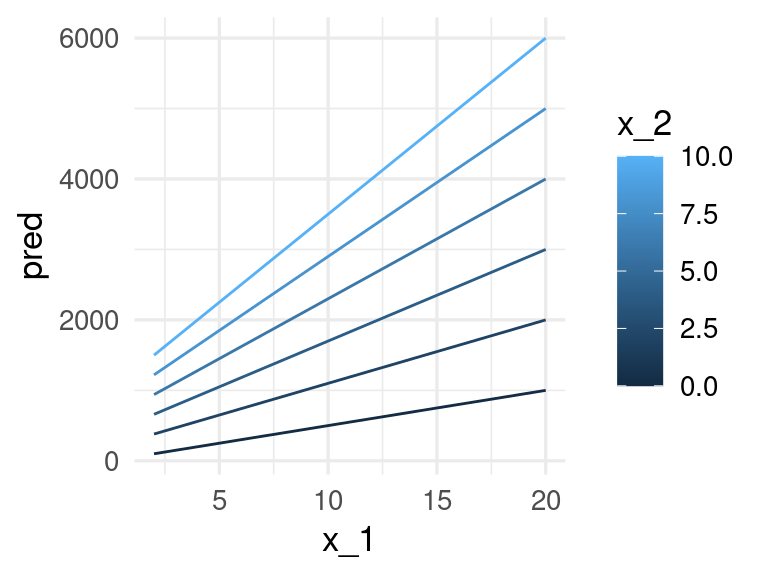
Una de las maneras más simples que podemos intentar para predecir \(y\) en función de las \(x_j\)´s es mediante una suma ponderada de los valores de las \(x_j's\), usando una función de la forma
\[f_\beta (x) = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_p x_p,\] En este caso, escoger una función particular de esta familia, dada una muestra de entrenamiento \({\mathcal L}\), consiste en encontrar encontrar valores apropiados de las \(\beta\)’s, para construir un predictor:
\[\hat{f}(x) = \hat{\beta}_0 + \hat{\beta}_1 x_1 + \hat{\beta}_2 x_2 \cdots + \hat{\beta} x_p\] y usaremos esta función \(\hat{f}\) para hacer predicciones \(\hat{y} =\hat{f}(x)\).
Ejemplos
Queremos predecir las ventas futuras anuales \(y\) de una tienda que se va a construir en un lugar dado. Las variables que describen el lugar son \(x_1 = trafico\_peatones\), \(x_2=trafico\_coches\). En una aproximación simple, podemos suponer que la tienda va a capturar una fracción de esos tráficos que se van a convertir en ventas. Quisieramos predecir con una función de la forma \[f_\beta (peatones, coches) = \beta_0 + \beta_1\, peatones + \beta_2\, coches.\] Por ejemplo, después de un análisis estimamos que
\(\hat{\beta}_0 = 1000000\) (ventas base, si observamos tráficos igual a 0: es lo que va a atraer la tienda)
\(\hat{\beta}_1 = (200)*0.02 = 4\) (capturamos 2% del tráfico peatonal, y cada capturado gasta 200 pesos)
\(\hat{\beta}_2 = (300)*0.01 =3\) (capturamos 1% del tráfico de autos, y cada capturado gasta 300 pesos)
Entonces haríamos predicciones con \[\hat{f}(peatones, coches) = 1000000 + 4\,peatones + 3\, coches.\] El modelo lineal es más flexible de lo que parece en una primera aproximación, porque tenemos libertad para construir las variables de entrada a partir de nuestros datos. Por ejemplo, si tenemos una tercera variable \(estacionamiento\) que vale 1 si hay un estacionamiento cerca o 0 si no lo hay, podríamos definir las variables
\(x_1= peatones\)
\(x_2 = coches\)
\(x_3 = estacionamiento\)
\(x_4 = coches*estacionamiento\)
Donde la idea de agregar \(x_4\) es que si hay estacionamiento entonces vamos a capturar una fracción adicional del trafico de coches, y la idea de \(x_3\) es que la tienda atraerá más nuevas visitas si hay un estacionamiento cerca. Buscamos ahora modelos de la forma \[f_\beta(x_1,x_2,x_3,x_4) = \beta_0 + \beta_1x_1 + \beta_2 x_2 + \beta_3 x_3 +\beta_4 x_4\] y podríamos obtener después de nuestra análisis las estimaciones - \(\hat{\beta}_0 = 800000\) (ventas base) - \(\hat{\beta}_1 = 4\) - \(\hat{\beta}_2 = (300)*0.005 = 1.5\) - \(\hat{\beta}_3 = 400000\) (ingreso adicional si hay estacionamiento por nuevo tráfico) - \(\hat{\beta}_4 = (300)*0.02 = 6\) (ingreso adicional por tráfico de coches si hay estacionamiento)
y entonces haríamos predicciones con el modelo \[\hat{f} (x_1,x_2,x_3,x_4) = 800000 + 4\, x_1 + 1.5 \,x_2 + 400000\, x_3 +6\, x_4\]
Variables derivadas
Nótese que cuando usamos modelos lineales, es necesario considerar qué entradas usar para construir el modelo de forma que la estructura lineal sea razonable. - Estas entradas son construidas a partir de las variables originales - Agregar variables tiene dos efectos: disminuye el sesgo, y también puede reducir el sesgo irreducible. - Omitir o simplificar estos modelos disminuyen típicamente la varianza pero pueden aumentar el sesgo irreducible.
En este caso particular, teníamos peatones, coches y estacionamiento, pero construimos también el producto de tráfico de coches y estacionamiento, pues la relación de ventas con coches es diferente dependiendo de sí la tienda tiene estacionamiento o no.
4.1 Aprendizaje de coeficientes (ajuste)
En el ejemplo anterior, los coeficientes fueron calculados (o estimados) usando experiencia, reglas, argumentos teóricos, o quizá otras fuentes de datos (como estudios o encuestas, conteos, etc.)
Ahora quisiéramos construir un algoritmo para aprender estos coeficientes del modelo \[f_\beta (x) = \beta_0 + \beta_1 x_1 + \cdots \beta_p x_p\] a partir de una muestra de entrenamiento de datos históricos de tiendas que hemos abierto antes: \[{\mathcal L}=\{ (x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}), \ldots, (x^{(N)}, y^{(N)}) \}\] El criterio de ajuste (algoritmo de aprendizaje) más usual para regresión lineal es el de mínimos cuadrados.
Construimos las predicciones (ajustados) para la muestra de entrenamiento: \[ f_\beta (x^{(i)}) = \beta_0 + \beta_1 x_1^{(i)}+ \cdots + \beta_p x_p^{(i)}\]
Y consideramos las diferencias de los ajustados con los valores observados:
\[e^{(i)} = y^{(i)} - f_\beta (x^{(i)})\]
La idea entonces es minimizar la suma de los residuales al cuadrado, para intentar que la función ajustada pase lo más cercana a los puntos de entrenamiento que sea posible. La función de pérdida que utilizamos más frecuentemente es la pérdida cuadrática, dada por:
Hay varias maneras de resolver este problema: puede hacerse analíticamente con álgebra lineal, o con algún método numérico como descenso máximo (que puede escalarse fácilmente). Típicamente la función objetivo es convexa, y la solución es única, excepto en casos degenerados que podremos evitar más adelante usando regularización.
Observación: Como discutimos al final de la sección anterior, minimizar directamente el error de entrenamiento para encontrar los coeficientes puede resultar en en un modelo sobreajustado/con varianza alta/ruidoso. Hay cuatro grandes estrategias para mitigar este problema: restringir o estructurar la familia de funciones, penalizar la función objetivo, perturbar la muestra de entrenamiento, o cambiar el proceso de minimización perturbando la función objetivo en cada paso o deteniendo el proceso antes de llegar a un mínimo sobreajustado. El método mas común es cambiar la función objetivo, que discutiremos más adelante en la sección de regularización.
4.2 Ingeniería de entradas
Algunas veces, encontrar la estructura apropiada puede requerir más trabajo que simplemente escoger una familia de modelos. Por ejemplo, en el caso de precios de casa, vimos que podríamos mejorar el ajuste haciendo que el coeficiente de área habitable dependiera de la calidad de los terminados @ref(medicioncostosa).
Usualmente tendremos que hacer varias transformaciones para obtener buen desempeño de un modelo lineal. En la siguientes secciones mostramos algunas de las más usuales.
4.3 Variables categóricas
En primer lugar, podemos incluir variables categóricas creando variables numéricas 0-1 para cada categoría. Por ejemplo para la variable calidad sótano:
# A tibble: 5 × 2
calidad_sotano n
<chr> <int>
1 Ex 89
2 Fa 23
3 Gd 457
4 TA 500
5 <NA> 26
El mejor nivel es Ex (excelente), luego sigue Gd (bueno), luego Fa (razonable) y finalmente TA (típico)). Hay otro nivel Po (Malo) que no aparece en estos datos.
En primer lugar, podemos codificar los valores faltantes, que en este caso indican casas sin sótano:
# A tibble: 5 × 2
calidad_sotano n
<fct> <int>
1 TA 500
2 Ex 89
3 Fa 23
4 Gd 457
5 no_sótano 26
Ahora convertimos a codificación dummy:
set.seed(7)receta_dummy <-recipe( ~ calidad_sotano, casas_entrena) |>step_unknown(calidad_sotano, new_level ="no_sótano") |>step_relevel(calidad_sotano, ref_level ="TA") |>step_dummy(calidad_sotano, keep_original_cols =TRUE)# preparar recetareceta_dummy_prep <-prep(receta_dummy) # extrae los datos de entrenamiento preprocesadosreceta_dummy_prep |>juice() |>sample_n(10) |>gt() |>tab_options(table.font.size =10)
calidad_sotano
calidad_sotano_Ex
calidad_sotano_Fa
calidad_sotano_Gd
calidad_sotano_no_sótano
TA
0
0
0
0
Gd
0
0
1
0
Ex
1
0
0
0
Ex
1
0
0
0
TA
0
0
0
0
TA
0
0
0
0
TA
0
0
0
0
TA
0
0
0
0
TA
0
0
0
0
TA
0
0
0
0
Nótese que no hay columna para el nivel TA, que tomamos como referencia. Incluir esta columna sería redundante, pues tenemos una constante en el predictor. En general, cuando una variable categórica tiene \(k\) niveles, esta codificación produce \(k-1\) columnas binarias.
Veamos qué pasa cuando preprocesamos datos de prueba (para después poder hacer predicciones):
prueba_casas <-testing(casas_split)# supongamos que un nuevo nivel apareceprueba_casas$calidad_sotano[1] <-"no visto antes"datos <-bake(receta_dummy_prep, prueba_casas)
Warning: There are new levels in a factor: no visto antes
New levels will be coerced to `NA` by `step_unknown()`.
Consider using `step_novel()` before `step_unknown()`.
Warning: There are new levels in a factor: NA
En este caso, podemos hacer nuestro flujo más robusto incluyendo un nuevo nivel en los factores donde pondremos casos no vistos. Modificamos nuestra receta:
prueba_casas <-testing(casas_split)# supongamos que un nuevo nivel apareceprueba_casas$calidad_sotano[1] <-"no visto antes"datos <-bake(receta_dummy_prep, prueba_casas)datos |>head() |>gt() |>tab_options(table.font.size =10)
calidad_sotano
calidad_sotano_Ex
calidad_sotano_Fa
calidad_sotano_Gd
calidad_sotano_nuevo
calidad_sotano_no_sótano
nuevo
0
0
0
1
0
Ex
1
0
0
0
0
TA
0
0
0
0
0
Gd
0
0
1
0
0
TA
0
0
0
0
0
TA
0
0
0
0
0
Y podemos ignorar el nuevo nivel al hacer predicciones (que equivale a ponerlo en la categoría de referencia, que en este caso es TA), o podemos lidiar de manera ad-hoc con este nivel.
Otro problema con el que podemos encontrarnos es variables categóricas que son muy ralas. Por ejemplo, una variable que tiene muchas categorías y algunas de ellas tienen muy pocos datos, además de que es probable que observemos nuevas categorías en el futuro. Por ejemplo, para la variable de zona:
En este caso, tenemos muchas categorías, algunas con muy pocos datos, y es posible que observemos nuevos datos. Una técnica es agrupar los datos de baja cardinalidad en un nuevo nivel (incluyendo categorías no observadas en entrenamiento):
En este caso, las zonas de baja frecuencia fueron agrupadas en la categoría “otras”. Si observamos un nuevo nivel al momento de predicción:
prueba_casas <-testing(casas_split)# supongamos que un nuevo nivel apareceprueba_casas$nombre_zona[1] <-"Xochimilco"datos <-bake(prep(receta_vecindario), prueba_casas)datos |>head() |>gt() |>tab_options(table.font.size =10)
nombre_zona_BrDale
nombre_zona_BrkSide
nombre_zona_ClearCr
nombre_zona_CollgCr
nombre_zona_Crawfor
nombre_zona_Edwards
nombre_zona_Gilbert
nombre_zona_IDOTRR
nombre_zona_MeadowV
nombre_zona_Mitchel
nombre_zona_NAmes
nombre_zona_NoRidge
nombre_zona_NridgHt
nombre_zona_NWAmes
nombre_zona_OldTown
nombre_zona_Sawyer
nombre_zona_SawyerW
nombre_zona_Somerst
nombre_zona_StoneBr
nombre_zona_SWISU
nombre_zona_Timber
nombre_zona_otras
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
0
0
0
0
0
0
0
0
0
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
0
0
0
0
0
0
0
0
0
0
0
El proceso general es (ver por ejemplo esta lista):
Variables categóricas
Establecemos los niveles que puede tener cada variable, incluyendo la posibilidad de categorías nuevas al momento de predecir, y categorías para valores no disponibles (NAs) (es posible también imputar con algún método en caso necesario).
Reorganizamos factores dependiendo del problema. Por ejemplo, incluir categorías de baja frecuencia en una categoría separada, o manipulaciones ad-hoc dependiendo del problema.
Sustituimos variables categóricas con \(K\) niveles en \(K-1\) columnas indicadoras de los niveles (estableciendo) alguna categoría como referencia. Esto no es estrictamente necesario en otros métodos, o si utilizamos regularización (ver sección siguiente).
4.4 Interacciones
Otra manera de expandir nuestro modelo es la utilización de interacciones, que muchas veces son clave para tener éxito con modelos lineales. Vimos ejemplos de interacciones en el ejemplo de las casas (@ref(medicioncostosa)) y en el primer ejemplo de ventas de tiendas que dependían del tráfico.
Ejemplo
Si \(x_1\) es el área en metros cuadrados de una casa, y \(x_2\) una calificación numérica de su calidad, podemos considerar el modelo sin interacciones:
\[\beta_0 + \beta_1x_1 + \beta_2 x_2\]
Pero no tiene mucho sentido que el efecto marginal de \(x_1\) sea constante para cualquier nivel de calidad, y tampoco que la calidad de terminados agregue una cantidad fija al precio de la casa sin tomar en cuenta su tamaño. Podemos remediar esto creando una nueva variable que es le producto de \(x_1\) y \(x_2\):
\[(\beta_0 + \beta_2x_2) + (\beta_1 + \beta_3x_2)x_1 = \gamma_0 + \gamma_1x_1\] De modo que es lineal en \(x_1\). La diferencia es que cuando cambia \(x_2\), la recta que ajustamos es diferente.
Y vemos que cuando la calidad es baja, el precio por metro cuadrado es más bajo que cuando la calidad es alta. Otra manera de pensar esto es que la inclusión de la interacción produce curvas marginales que rotan dependiendo del valor de otras variables.
Pregunta. ¿puedes pensar en otros casos donde las interacciones deben jugar un papel importante?
Interacciones
Transformamos las variables categóricas a dummies. Transformamos las variables numéricas si es necesario (normalizar, aplicar transformación no lineal, etc.)
Incluimos interacciones de la siguiente forma:
Para la interaccion de dos variables numéricas \(x_1\) y \(x_2\) agregamos el producto \(x_3 = x_1x_2\).
Para interacción de una variable categórica \(g\) con una numérica \(x\) podemos hacer el mismo procedimiento multiplicando la variable categórica por cada una de las variable dummy que creamos a partir de \(g\). Esto en efecto produce una pendiente para \(x\) dependiendo del valor que toma \(g\).
4.5 Ejemplo: precios de casas
En el ejemplo de precios de casas, por ejemplo, es claro que el efecto en ventas del tamaño de las áreas (habitable, garage, etc.) depende de la calidad de los terminados, como vimos en la introducción. En la siguiente receta de preprocesamiento:
Cortamos calidad general en 5 grupos: este paso no es necesario y puede dañar el desempeño, pero es consistente con el análisis que hicimos anteriormente.
Lidiamos con niveles nuevos y los ponemos en una categoría “nuevo” (para que nuestro modelo no falle al momento de predicción)
Ponemos los faltantes de calidad sotano y garage en una categoría nueva (no tienen sótano y/o garage)
Agrupamos las zonas con pocas observaciones en una categoría de “Otros”
Quitamos los NA’s de área garage y área sotano, que deben ser igual a 0 cuando no existen estas características.
Creamos variables dummy de todas las variables categóricas
Incluimos interacciones de distintas áreas con las dummy correspondientes, incluyendo zona con área habitable
Finalmente, eliminamos para el ajuste aquellas variables que tengan varianza cercana a cero (500 /1 quiere decir que elimina cualquier variable cuyo conteo del valor más común entre el conteo de la siguiente es mayor a 500).
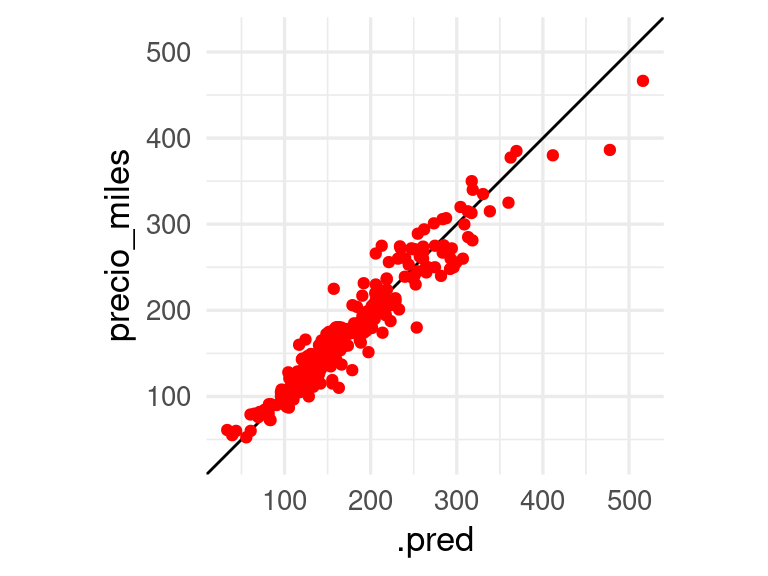
Aunque no es de interés particular para nosotros por el momento, examinamos los coeficientes (que no son tan simples de interpretar como discutiremos más adelante):
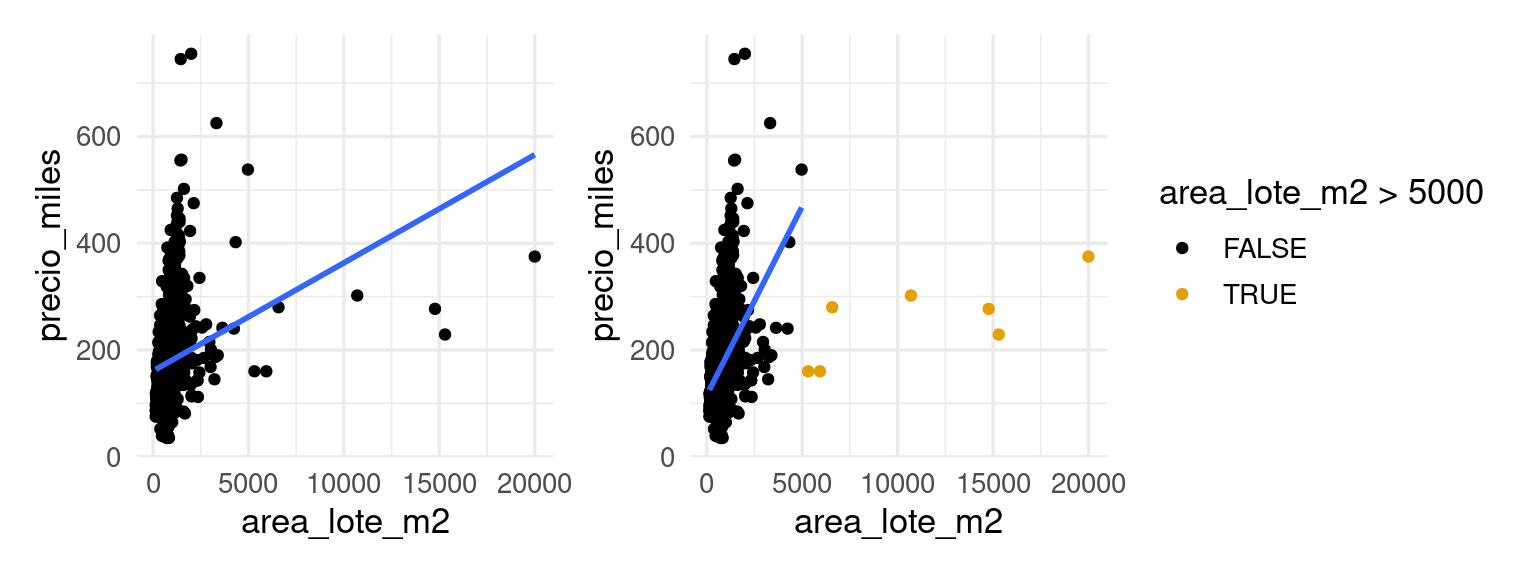
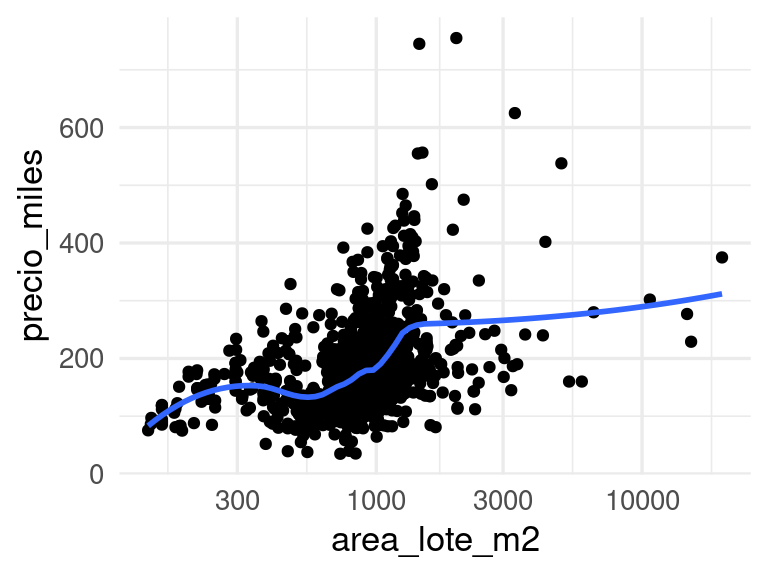
Y notamos que hay algunos valores grandes que pueden perturbar el ajuste lineal. Esto puede producir varianza alta en las predicciones, pues el ajuste depende mucho de unos cuantos valores de entrenamiento. Una solución puede ser transformar la entrada por ejempo usando el logaritmo, que comprime la cola derecha de la distribución de la variable que tiene mucho sesgo:
ggplot(casas_entrena, aes(x = area_lote_m2, y = precio_miles)) +geom_point() +geom_smooth(method ="loess", span =0.5, se =FALSE) +scale_x_log10()
`geom_smooth()` using formula = 'y ~ x'
Nótese que probablemente tendremos que agregar más flexibilidad en nuestro predictor para capturar apropiadamente la información en esta variable.
4.7 No linealidad y splines
En algunos casos, la relación de una variable de entrada con la predicción es no lineal. Podemos entonces incluír entradas derivadas de la original usando transformaciones no lineales: por ejemplo, transformar entradas usando el logaritmo, o agregar el cuadrado o la raíz de las variables de entrada.
Una de las maneras más simples y menos problemáticas de hacer esto es usando splines naturales para modelar, que son funciones cúbicas por tramos dos veces diferenciables. Los tramos están definidos por nudos que podemos definir por ejemplo igualmente espaciados en los datos.
Estos dos son ejemplos de funciones cúbicas por tramos y dos veces diferenciables, con nudos en 0, 33, 66 y 100. Su forma particular depende de tres coeficientes, que pueden pensarse también como definidos por dónde tienen que pasar la curva en \(y\) para los valores \(x = 33, 66\) y \(100\). Extrapolan linealmente fuera del rango de los datos.
La ventaja de utilizar estos splines es que son estables en el cálculo, pues a lo más utilizan potencias cúbicas, y la complejidad puede aumentarse incrementando el número de nodos.
Ejemplo
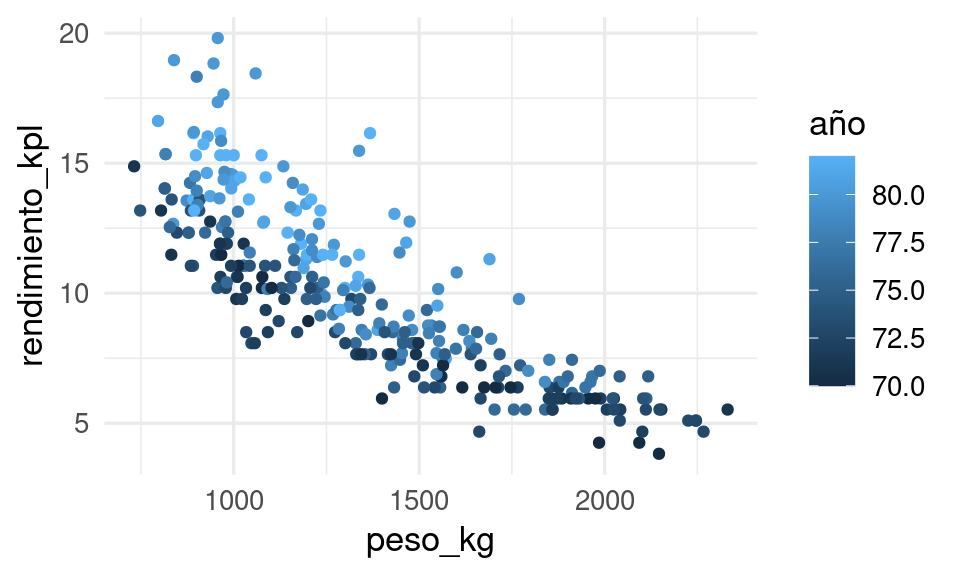
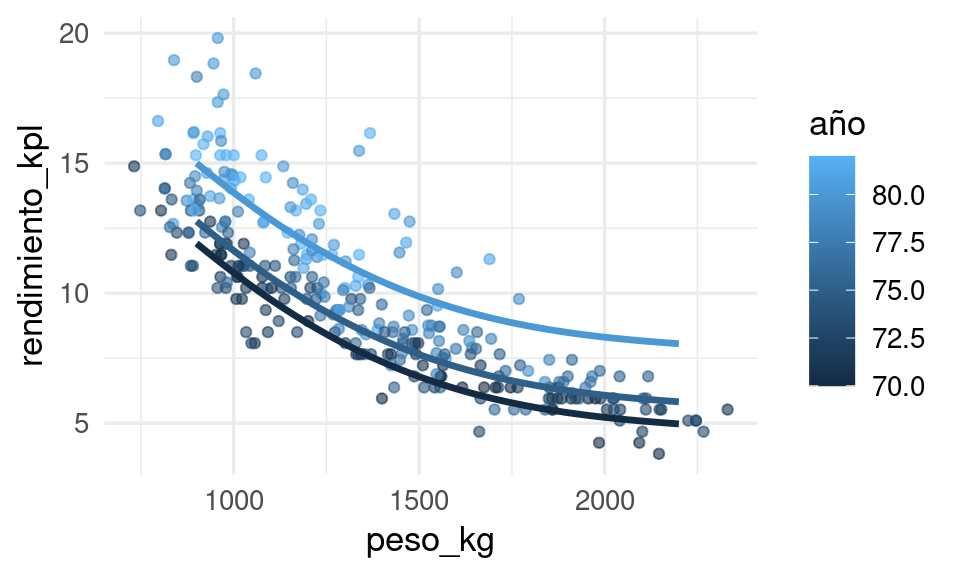
Revisamos nuestro ejemplo de rendimiento de coches:
Vamos a separar en muestra de entrenamiento y de prueba estos datos. Podemos hacerlo como sigue (75% para entrenamiento aproximadamente en este caso, así obtenemos alrededor de 100 casos para prueba):
Nótese que tenemos 4 entradas en lugar de las 2 originales, pues creamos dos transformaciones no lineales de peso_kg. El modelo es lineal en estas 4 variables, pero no en las 2 originales. Ajustamos:
flujo_ajustado <-fit(flujo, datos_entrena)
Y ahora podemos graficar los resultados y vemos cómo pudimos capturar la relación no lineal entre peso y rendimiento: