Como vimos en el ejemplo anterior, en algunos casos podemos construir modelos lineales de complejidad considerable (por ejemplo, transformando variables, incluyendo interacciones). De manera que aún cuando muchas veces se considera un modelo lineal como “simple” o de “baja complejidad”, es posible que la variabilidad de las estimaciones sea grande y sobreajustar.
En este caso, minimizar el error cuadrático medio sobre la muestra de entrenamiento como vimos en la sección anterior puede no ser muy buena idea. En esta parte veremos una estrategia básica para “limitar” el grado de ajuste que nuestro modelo lineal puede alcanzar con datos de entrenamiento, esperando que esto mejore el desempeño predictivo. En otras palabras, modificamos nuestra función objetivo para que las \(f(x)\) no sobreajusten a las \(y\). Este primera estrategia es llamada regularización, y consiste agregar una penalización por tamaño de los coeficientes a la función objetivo.
Veamos primero un ejemplo simulado.
5.1 Ejemplo: datos simulados y varianza
Consideremos un problema donde tenemos unas 100 entradas con 120 casos. Supondremos que la función verdadera es
\[f(x) = \sum_{j=1}^{100} \beta_j x_j\] con ciertos pesos o coeficientes \(\beta\) que fijaremos.
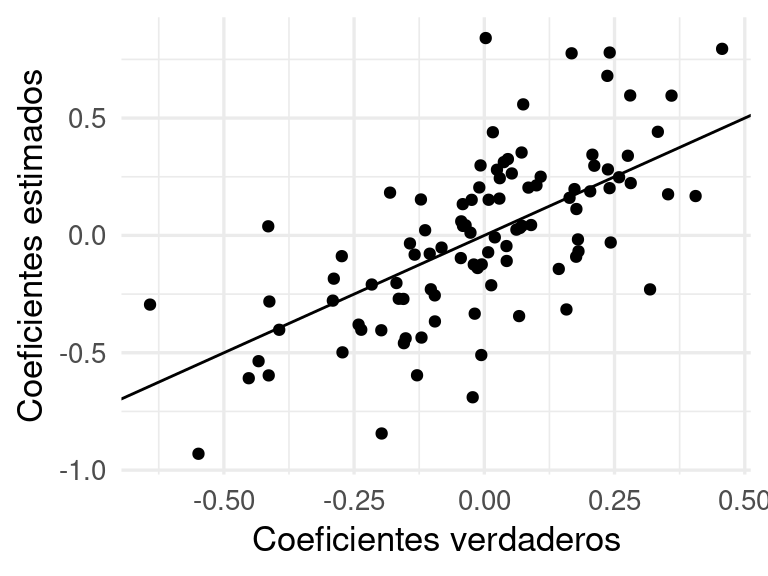
Extraemos los coeficientes y graficamos ajustados contra verdaderos:
coefs_1 <-tidy(mod_1) |>left_join(beta, by ="term")ggplot(coefs_1 |>filter(term !="(Intercept)"), aes(x = valor, y = estimate)) +geom_point() +xlab('Coeficientes verdaderos') +ylab('Coeficientes estimados') +geom_abline()
Y notamos que las estimaciones no son buenas. Podemos hacer otra simulación para confirmar que el problema es que las estimaciones son muy variables.
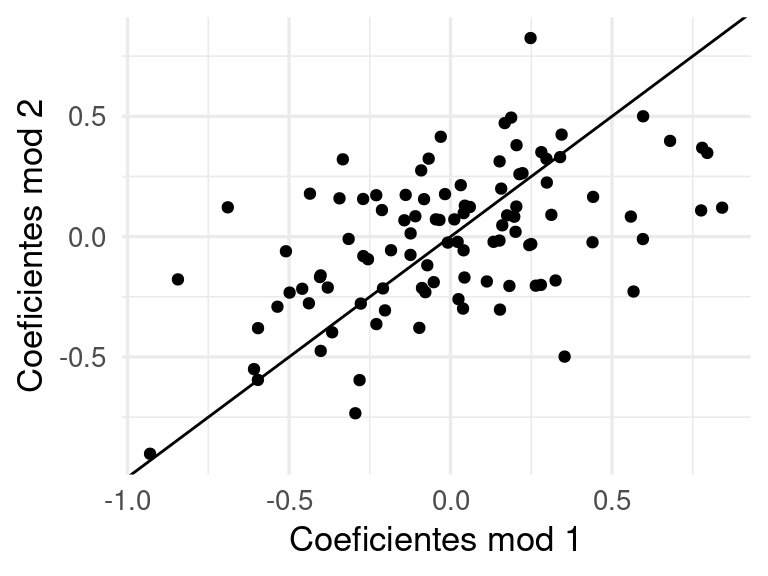
Con otra muestra de entrenamiento, vemos que las estimaciones tienen varianza alta.
datos_ent_2 <-sim_datos(n =120, beta = beta)mod_2 <-fit(flujo, datos_ent_2) |>extract_fit_engine()coefs_2 <-tidy(mod_2)qplot(coefs_1$estimate, coefs_2$estimate) +xlab('Coeficientes mod 1') +ylab('Coeficientes mod 2') +geom_abline(intercept=0, slope =1)
Warning: `qplot()` was deprecated in ggplot2 3.4.0.
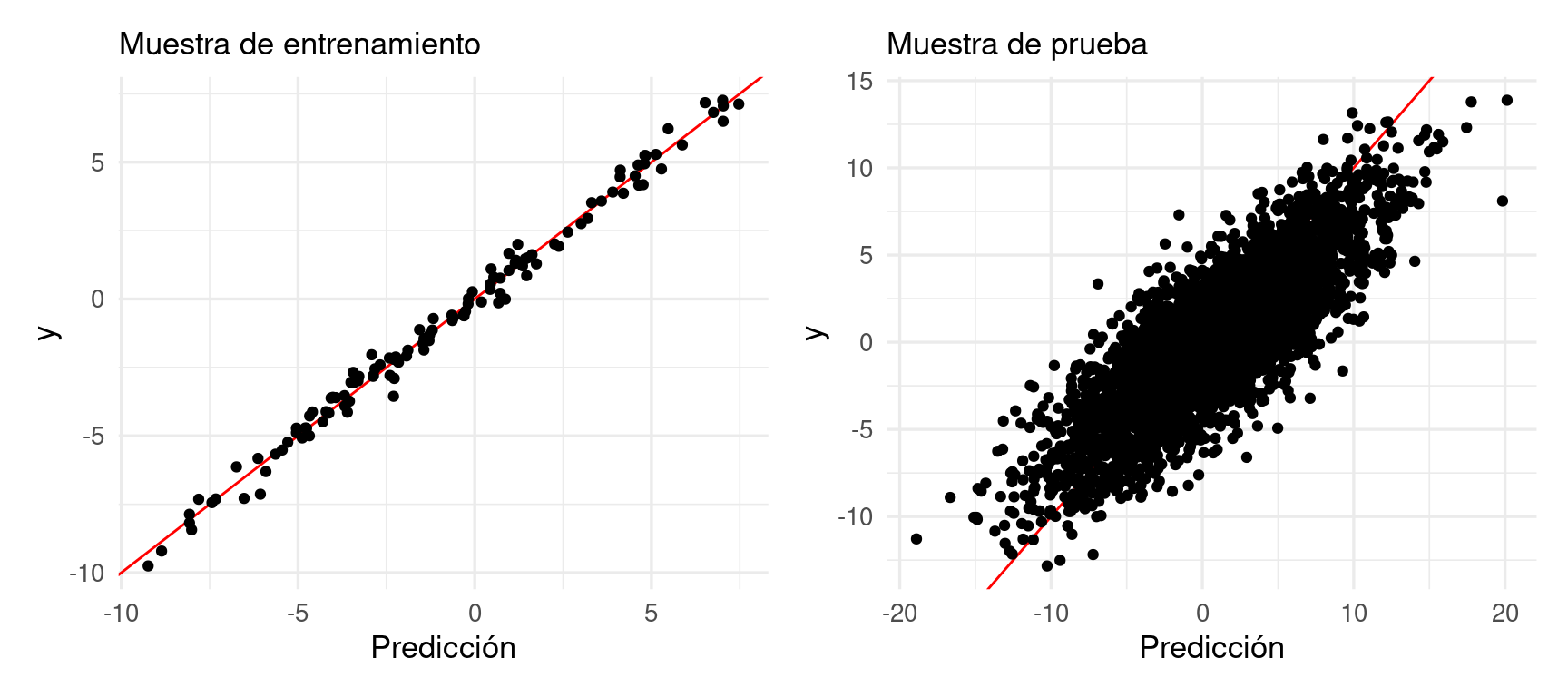
En la práctica, nosotros tenemos una sola muestra de entrenamiento. Así que, con una muestra de tamaño \(n=120\) como en este ejemplo, obtendremos típicamente resultados no muy buenos. Estos coeficientes ruidosos afectan nuestras predicciones de manera negativa, aún cuando el modelo ajustado parece reproducir razonablemente bien la variable respuesta:
Como el problema es la variabilidad de los coeficientes (en este ejemplo sabemos que no hay sesgo pues conocemos el modelo verdadero), podemos atacar este problema poniendo restricciones a los coeficientes, de manera que caigan en rangos más aceptables.
Una manera de hacer esto es restringir el rango de los coeficientes cambiando la función que minimizamos para ajustar el modelo lineal. Recordamos que la cantidad que queremos minimizar es
donde la suma es sobre los datos de entrenamiento. Queremos encontrar \(a =(\beta_0, \beta_1, \ldots, \beta_p)\) para resolver
\[\min_\beta D(\beta)\]
En el ejemplo que estamos considerando, vemos que existe mucha variación en los coeficientes obtenidos de muestra de entrenamiento a muestra de entrenamiento, y que algunos de ellos toman valores muy grandes positivos o negativos. Podemos entonces intentar resolver mejor el problema penalizado
Si escogemos un valor relativamente grande de \(\lambda > 0\), entonces terminaremos con una solución donde los coeficientes
no pueden alejarse mucho de 0, y esto previene parte del sobreajuste que observamos en nuestro primer ajuste. Otra manera de decir esto es: intentamos minimizar cuadrados, pero no permitimos que los coeficientes se alejen demasiado de cero, o ponemos un costo a soluciones que intentan “mover” mucho los coeficientes para ajustar mejor al conjunto de entrenamiento.
(Quitar unidades) Normalmente normalizamos las variables de entrada \(x\) para que tenga sentido penalizar todos los coeficientes con una misma \(\lambda\).
(Representación alternativa) También es posible poner restricciones sobre el tamaño de \(\sum_j \beta_j^2\), lo cual es equivalente al problema de penalización.
(Ordenada al origen) Usualmente no penalizamos la constante \(\beta_0\), de forma que si \(\lambda\) es muy grande, nuestro modelo ajustado predice simplemente la media de los datos de entrenamiento. En otro caso, nuestra predicción limite sería 0, lo cual rara vez tiene sentido.
Este tipo de penalización se llama muchas veces \(L_2\), o penalización ridge.
metricas <-metric_set(mae, rmse)res_1 <-metricas(preds_prueba, truth = y, estimate = .pred) |>mutate(tipo ="no penalizado")res_2 <-metricas(preds_prueba_2, truth = y, estimate = .pred) |>mutate(tipo ="penalizado")bind_rows(res_1, res_2) |>arrange(.metric) |>gt() |>fmt_number(.estimate, decimals =2)
.metric
.estimator
.estimate
tipo
mae
standard
2.34
no penalizado
mae
standard
1.27
penalizado
rmse
standard
2.95
no penalizado
rmse
standard
1.60
penalizado
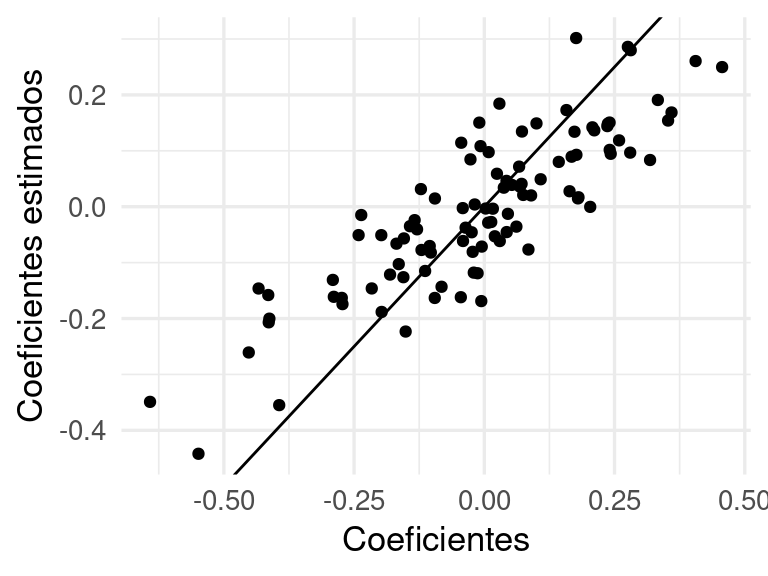
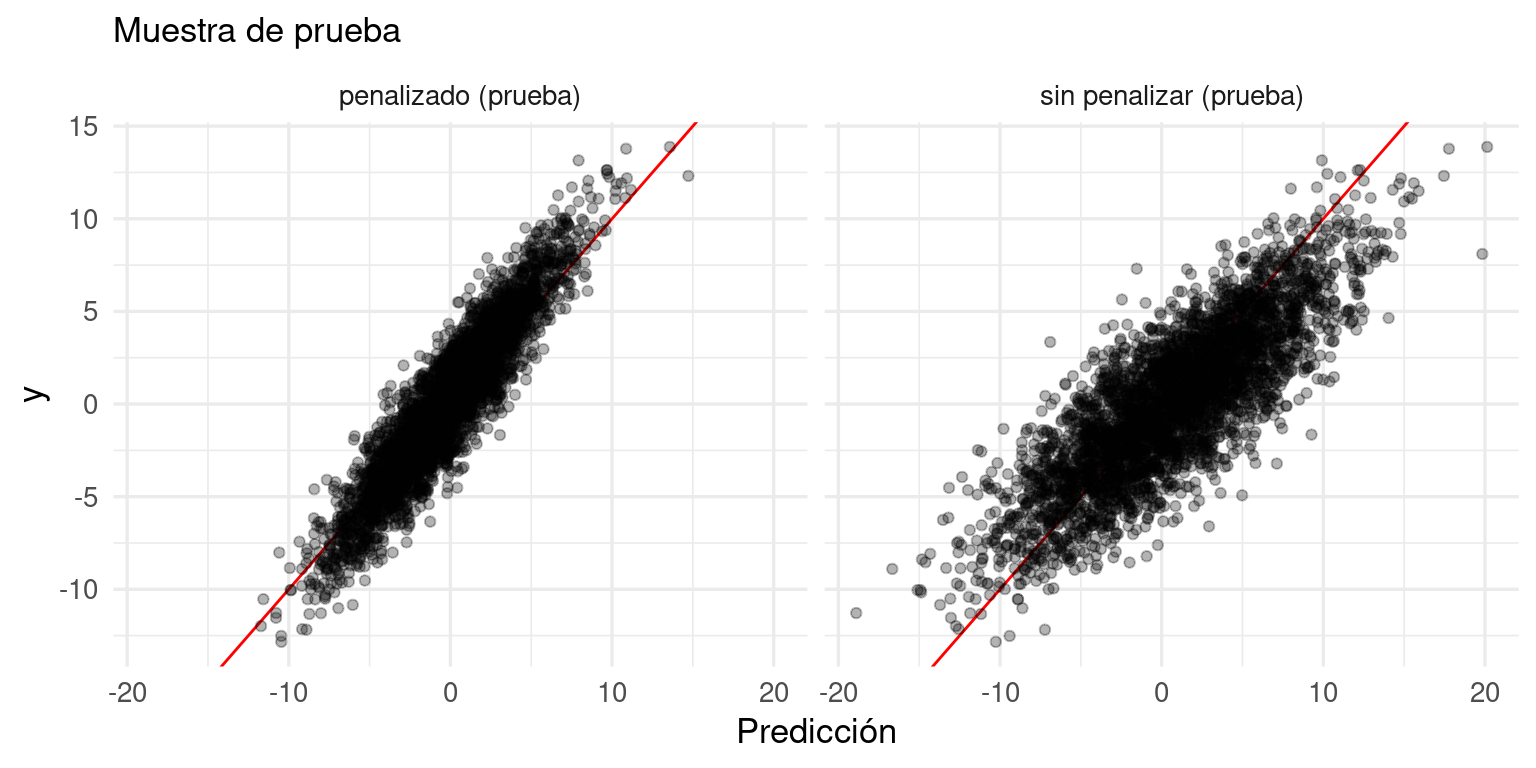
Y vemos que los errores de predicción se reducen considerablemente.
Obsérvese que esta mejora en varianza tiene un costo: un aumento en el sesgo (observa en los extremos de las predicciones regularizadas).
Sin embargo, lo que nos importa principalmente es reducir el error de predicción, y eso lo logramos escogiendo un balance sesgo-varianza apropiado para los datos y el problema.
Regularización L2
Cuando agregamos el término de penalización tipo ridge al error de entrenamiento como objetivo a minimizar en el ajuste, los coeficientes de la solución penalizada están encogidos con respecto a los no penalizados.
Regularizar reduce la varianza de los coeficientes a lo largo de distintas muestras de entrenamiiento, lo que reduce la posibilidad de sobreajuste.
Utilizamos regularización para reducir el error de predicción cuando el problema es variabilidad grande de los coeficientes (coeficientes ruidosos) en modelos relativamente grandes o con pocos datos de entrenamiento.
En general, a métodos donde restringimos el espacio de modelos o penalizamos ajustes complejos en la función de pérdida que nos interesa se llaman métodos con regularización. Un ejemplos es todos los modelos donde en lugar de considerar la función de perdida \(L\) solamente, consideramos minimizar
\[L(f) + \Omega(f),\] donde \(f\) es una medida de la complejidad, como puede ser: que la función \(f\) tiene oscilaciones grandes o pendientes grandes, tiene un número grande de discontinuidades, etc.
5.3 Ejemplo 2: penalización y estimaciones ruidosas
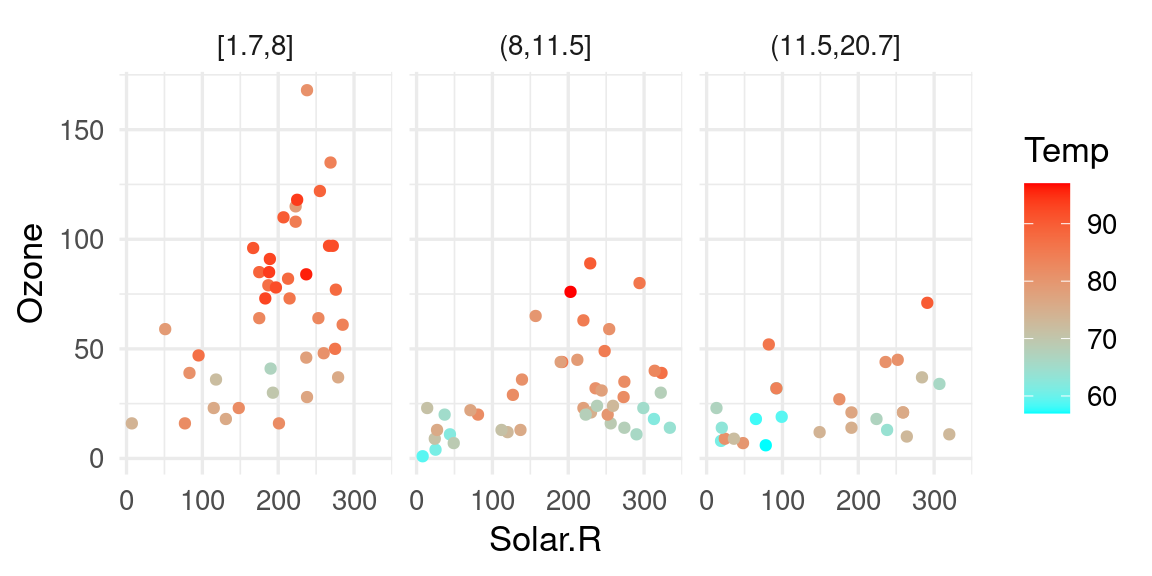
Consideremos los siguientes datos clásicos de Radiación Solar, Temperatura, Velocidad del Viento y Ozono para distintos días en Nueva York (Chambers et al. (1983)):
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
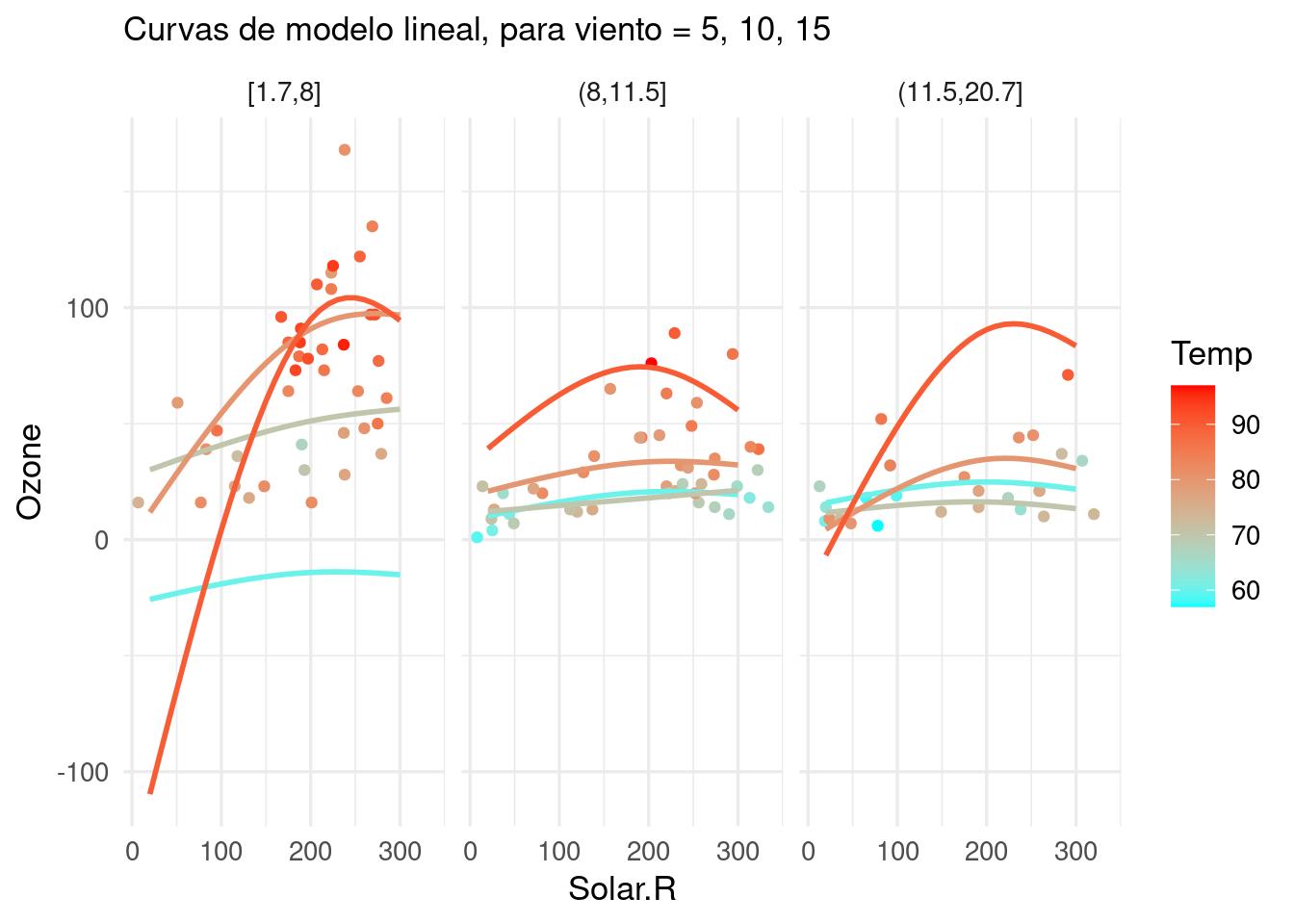
g_lineal
Nótese que algunos aspectos de este modelo parecen ser muy ruidosos: por ejemplo, el comportamiento de las curvas para el primer pánel (donde hay pocos datos de temperatura baja), el hecho de que en algunos casos parece haber curvaturas decrecientes e incluso predicciones negativas. No deberíamos dar mucho crédito a las predicciones de este modelo, y tiene peligro de producir predicciones desastrosas.
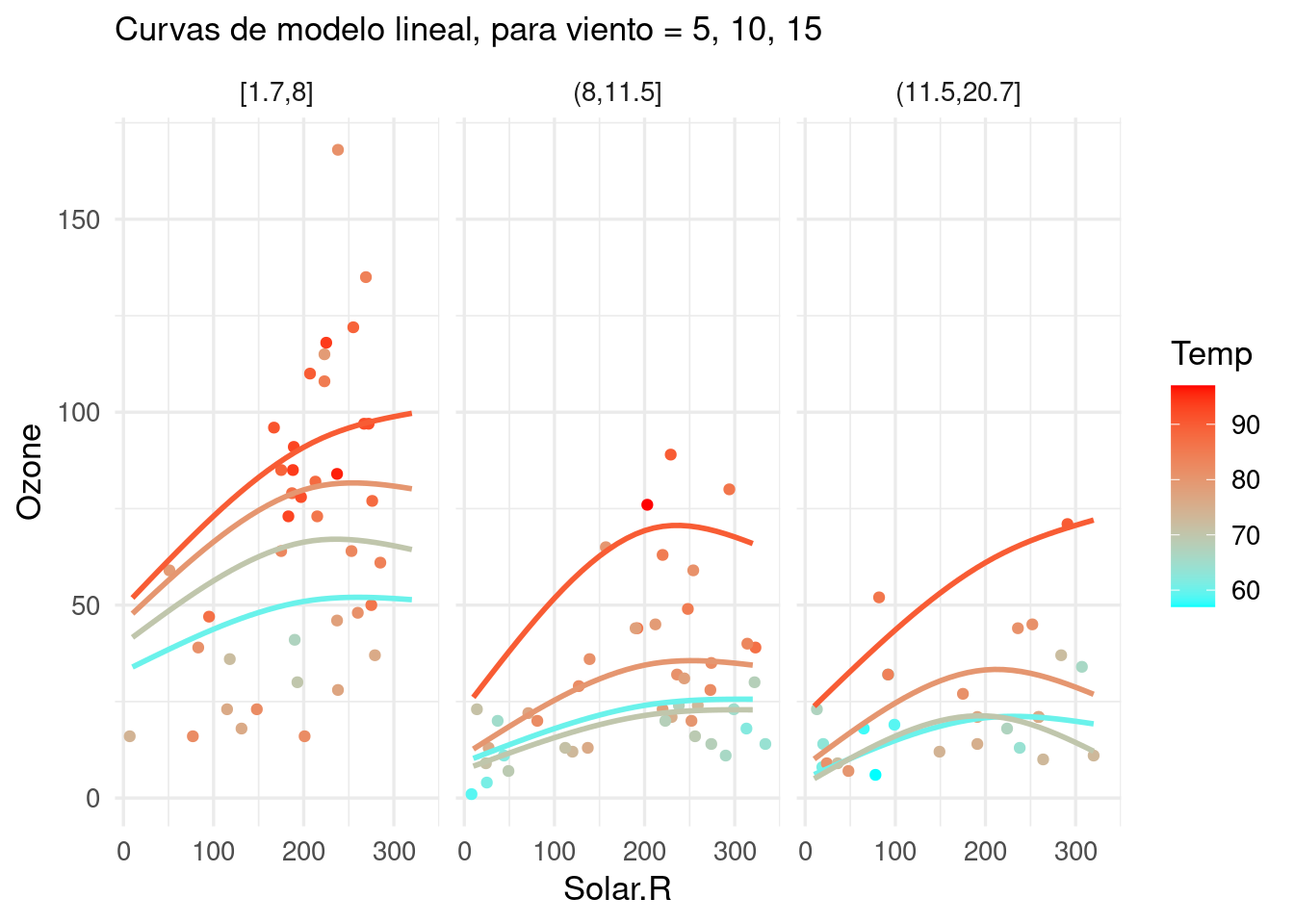
Sin embargo, si usamos algo de regularización:
ajuste_ozono <-workflow() |>add_recipe(receta_ozono) |>add_model(linear_reg(mixture =0, penalty =3.0) |>set_engine("glmnet", lambda.min.ratio =0)) |>fit(air)# nota: normalmente no es necesario usar lambda.min.ratio
5.4 Regresión ridge: escogiendo el parámetro de complejidad
Como vimos antes, no es posible seleccionar el parámetro \(\lambda\) usando la muestra de entrenamiento (¿con qué \(\lambda\) cómo se obtiene el menor error cuadrático medio sobre la muestra de entrenamiento). Usaremos un conjunto de validación relativamente grande
set.seed(191)source("../R/casas_traducir_geo.R")
Rows: 1460 Columns: 81
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (43): MSZoning, Street, Alley, LotShape, LandContour, Utilities, LotConf...
dbl (38): Id, MSSubClass, LotFrontage, LotArea, OverallQual, OverallCond, Ye...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 27 Columns: 3
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): Neighborhood
dbl (2): lat, long
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Construimos manualmente el conjunto de validación:
# creamos un objeto con datos de entrenamiento y de pruebaval_split <-manual_rset(casas_split |>list(), "validación")lambda_params <-parameters(penalty(range =c(-3, 3), trans =log10_trans()))lambda_grid <-grid_regular(lambda_params, levels =20)lambda_grid
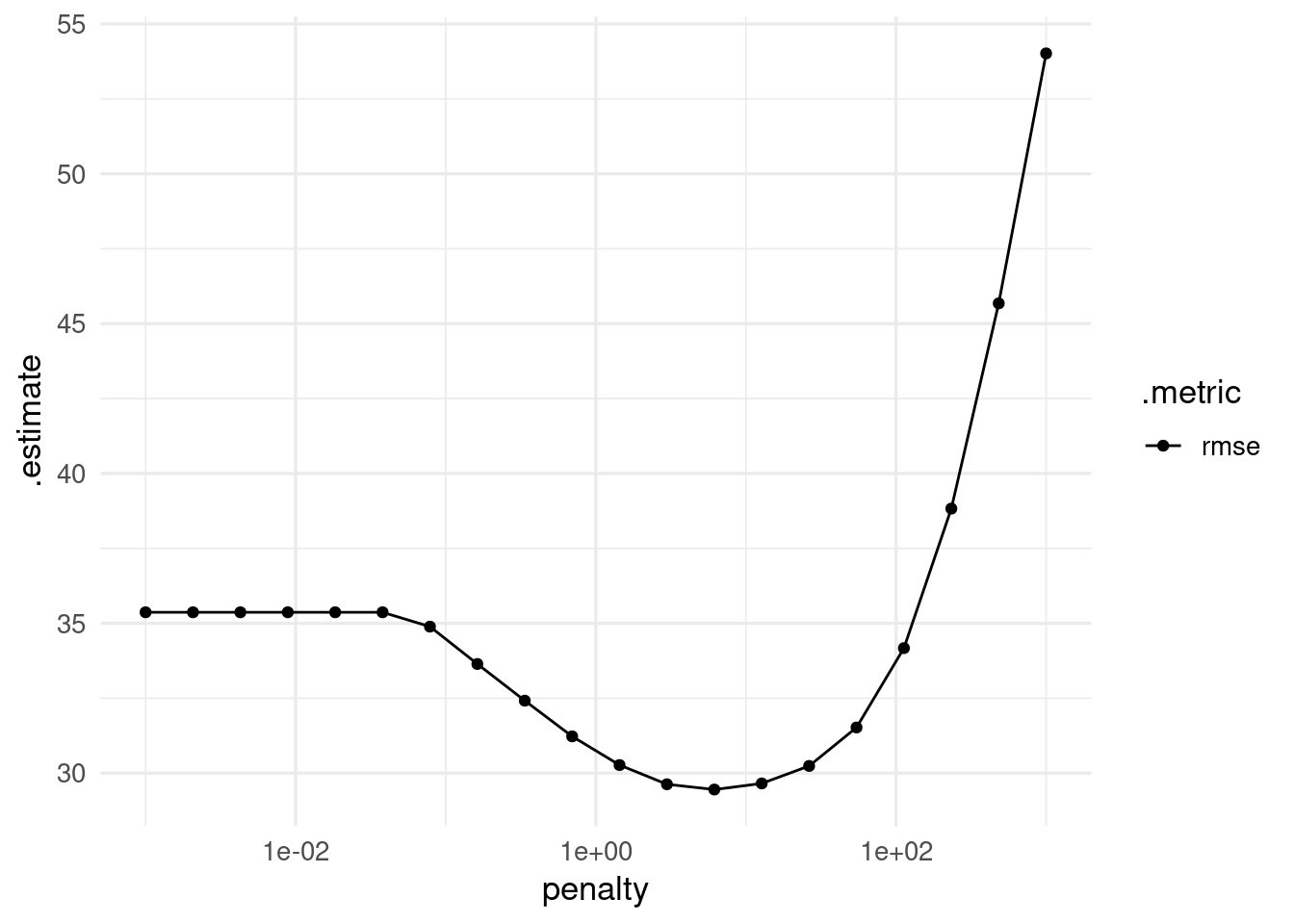
Y vemos que con una penalización alrededor de \(\lambda = 1\) podemos obtener mejor desempeño que con el modelo no regularizado.
Pregunta: en qué partes de la gráfica es relativamente grande la varianza? ¿en qué parte es relativamente grande el sesgo?
5.5 Regresión lasso
Se puede controlar la varianza de mínimos cuadrados de otras maneras. Cuando la varianza proviene también de la inclusión de variables que no necesariamente están relacionadas con la respuesta, podemos usar métodos de selección de variables, como en stepwise regression, por ejemplo.
Otra manera interesante de lograr mejor desempeño predictivo con modelos más parsimoniosos resulta de usar un término de penalización distinto al de ridge. En ridge, el problema que resolvemos es minimizar el objetivo
\[D(\beta) + \lambda \sum_{j=1}^p \beta_j^2\]
En regresión lasso, usamos una penalización de tipo \(L_1\):
\[D(a) + \lambda \sum_{j=1}^p |\beta_j|\] En un principio, no parece ser muy diferente a ridge. Veremos sin embargo que usar esta penalización también se puede ver como un proceso de selección de variables.
5.6 Lasso vs Ridge
Consideramos cómo predecir el porcentaje de grasa corporal a partir de distintas mediciones de dimensiones corporales:
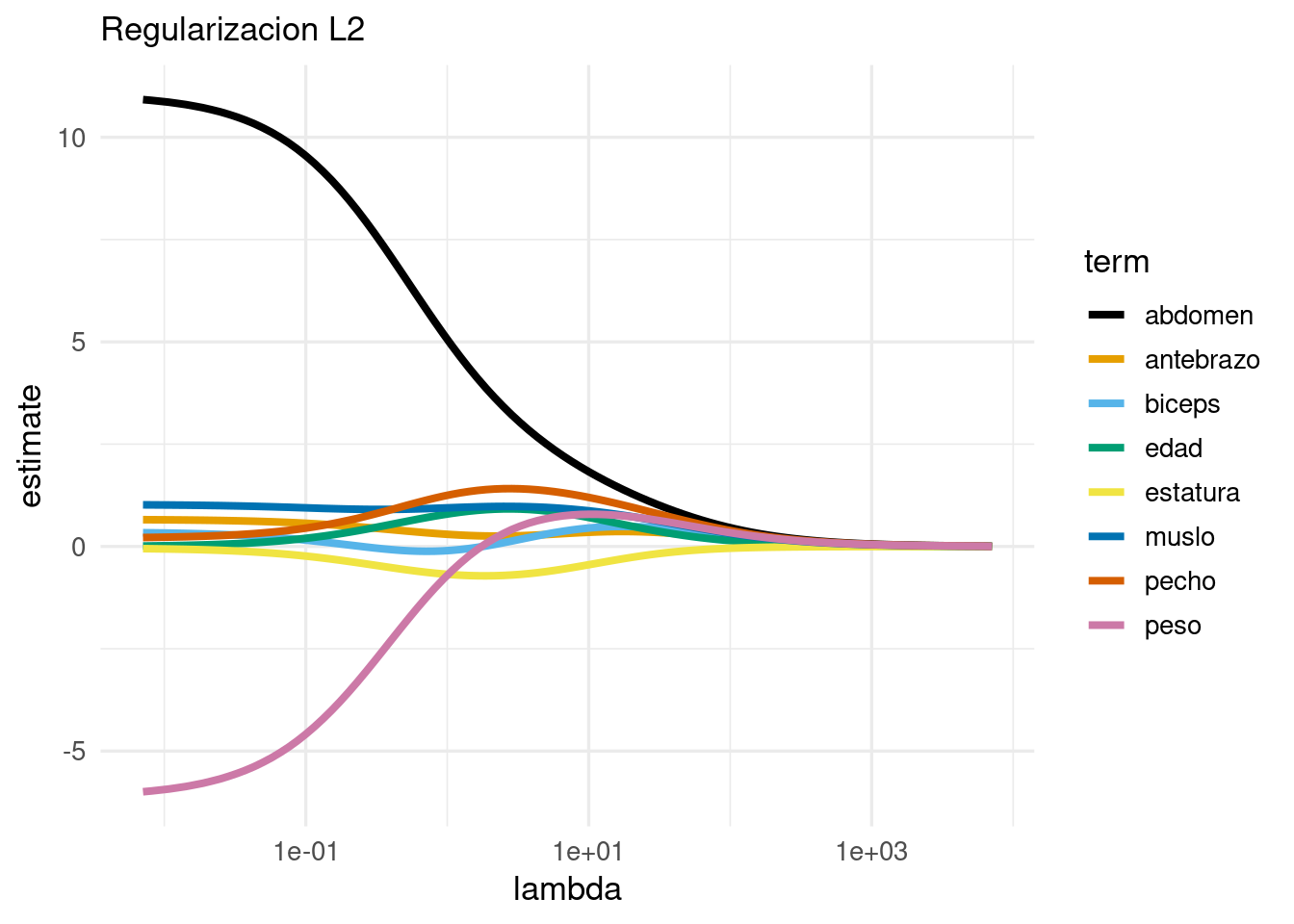
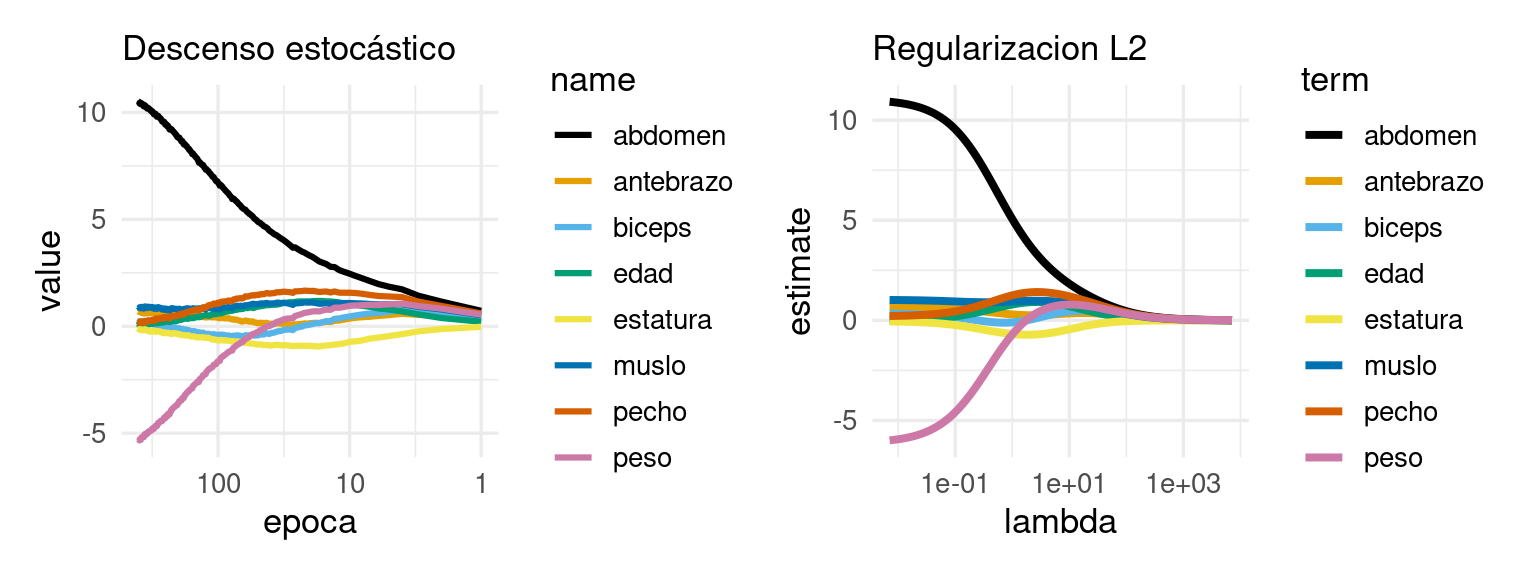
# nota: con glmnet no es necesario normalizar, pero aquí lo hacemos# para ver los coeficientes en términos de las variables estandarizadas:grasa_receta <-recipe(grasacorp ~ ., grasa_ent) |>update_role(cadera, cuello, muñeca, tobillo, rodilla, new_role ="ninguno") |>step_normalize(all_predictors())modelo_2 <-linear_reg(mixture =0, penalty =0) |>set_engine("glmnet", lambda.min.ratio =1e-20) flujo_2 <-workflow() |>add_model(modelo_2) |>add_recipe(grasa_receta)flujo_2 <- flujo_2 |>fit(grasa_ent) modelo_2 <-extract_fit_parsnip(flujo_2)coefs <- modelo_2 |>pluck("fit") |>tidy() |>filter(term !="(Intercept)")g_l2 <-ggplot(coefs, aes(x = lambda, y = estimate, colour = term)) +geom_line(size =1.4) +scale_x_log10() +scale_colour_manual(values = cbb_palette) +labs(subtitle ="Regularizacion L2")g_l2
Estas gráfica se llama traza de los coeficientes, y nos muestra cómo cambian los coefi´cientes conforme cambiamos la regularización. Nótese que cuando la regularización es chica, obtenemos algunos resultados contra-intuitivos como que el coeficiente de peso es negativo para predecir el nivel de grasa corporal. Cuando regularizamos más, este coeficiente es positivo. La razón de esto tiene qué ver con la correlación fuerte de las variables de entrada, por ejemplo:
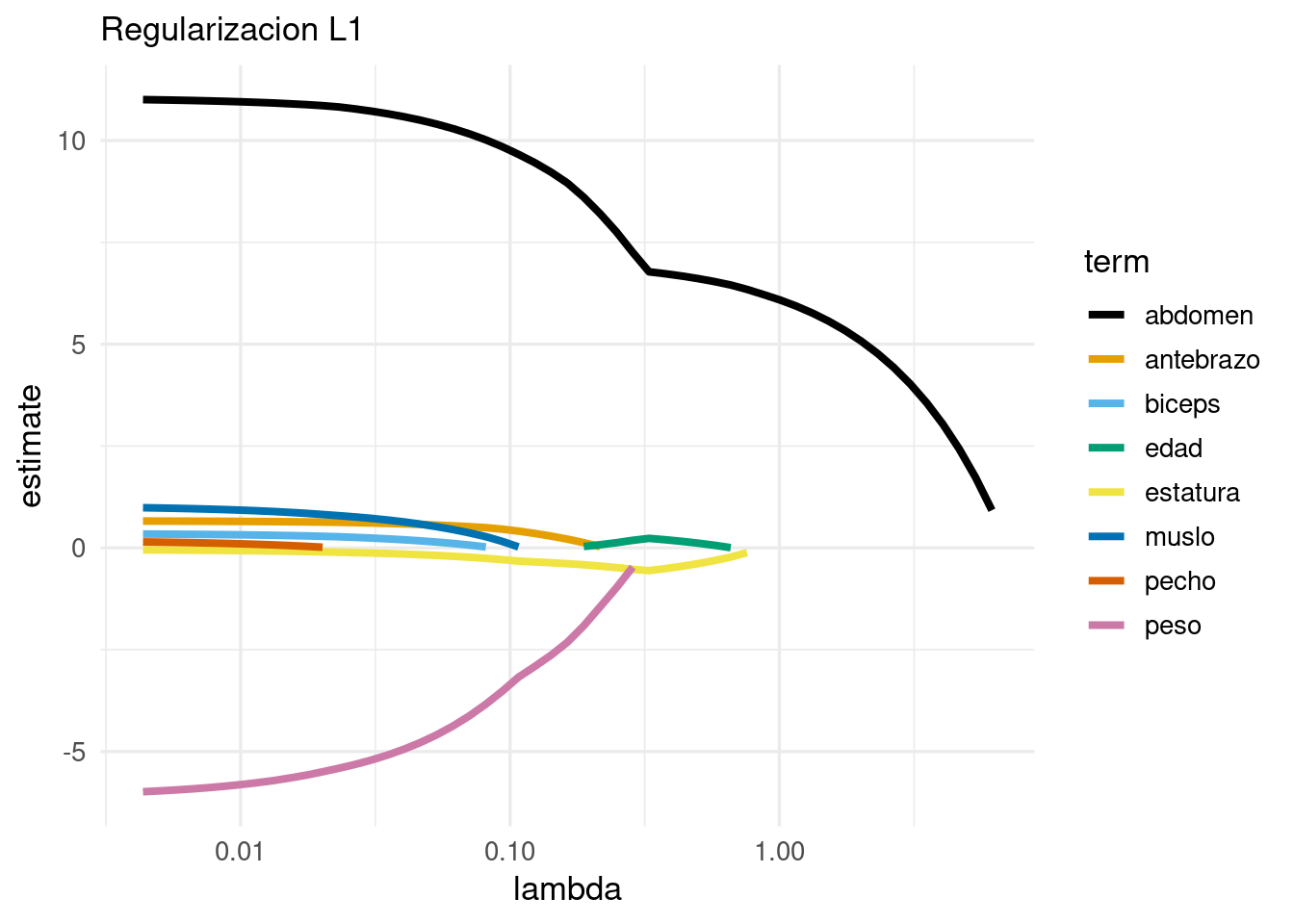
Y nótese que conforme aumentamos la penalización, algunas variables salen del modelo (sus coeficientes son cero). Por ejemplo, para un valor de \(lambda\) intermedio, obtenemos un modelo simple de la forma:
Y nótese que este modelo solo incluye 3 variables.La traza confirma que la regularización lasso, además de encoger coeficientes, saca variables del modelo conforme el valor de regularización aumenta.
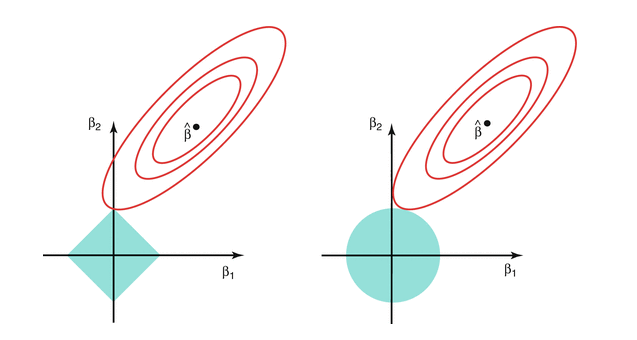
La razón de esta diferencia cualitativa entre cómo funciona lasso y ridge se puede entender considerando que los problemas de penalización mostrados arriba puede escribirse en forma de problemas de restricción. Por ejemplo, lasso se puede reescribir como el problema de resolver
\[\min_a D(\beta)\] sujeto a \[\sum_{i=1}^p |\beta_j| < t\] En la gráfica siguiente (tomada de Hastie, Tibshirani, y Friedman (2017)), lasso está a la izquierda y ridge está a la derecha, las curvas rojas son curvas de nivel de la suma de cuadrados \(D(a)\), y \(\hat{\beta}\) es el estimador usual de mínimos cuadrados de los coeficientes (sin penalizar). En azul está la restricción:
Ridge vs Lasso (Hastie, Tibshirani y Friedman)
Regularización para modelos lineales
En regresión ridge, los coeficientes se encogen gradualmente desde la solución no restringida hasta el origen. Ridge es un método de encogimiento de coeficientes. Regresión ridge es especialmente útil cuando tenemos varias variables de entrada fuertemente correlacionadas. Regresión ridge intenta encoger juntos coeficientes de variables correlacionadas para reducir varianza en las predicciones.
En regresión lasso, los coeficientes se encogen gradualmente, pero también se excluyen variables del modelo. Por eso lasso es un método de encogimiento y selección de variables. Lasso encoge igualmente coeficientes para reducir varianza, pero también comparte similitudes con regresión de mejor subconjunto, en donde para cada número de variables \(l\) buscamos escoger las \(l\) variables que den el mejor modelo. Sin embargo, el enfoque de lasso es más escalable y puede calcularse de manera más simple.
Nota: es posible también utilizar una penalización que mezcla ridge y lasso:
# elastic net = ridge + lasso# mixture es alpha y penalty es lambdamodelo_enet <-linear_reg(mixture =0.5, penalty =0.05)# y si queremos afinar:modelo_enet <-linear_reg(mixture =tune(), penalty =tune())
5.7 Regularización con descenso en gradiente
Otra forma de hacer regularización que se utiliza comunmente se basa en el método de minimización que usamos para obtener nuestra función \(\hat{f}\) para hacer predicciones. La idea es utilizar un método iterativo que comience con una \(f_0\) simple, y luego iterar a una nueva \(f_1\) que se adapta mejor a los datos pero no es muy diferente a \(f_0\). En lugar de seguir iterando hasta llegar a un mínimo de \(L(f),\) evaluamos con una muestra de prueba para encontrar un lugar apropiado para detenernos (early stopping). También podemos modificar \(L(f)\) en cada paso para evitar atorarnos en un mínimo sobreajustado.
Una manera de hacer esto es usando el método de descenso estocástico, (ver apéndices Apéndice A y Apéndice B) que consiste en:
En cada iteración \(i\) construimos una función de pérdida \(L^{(i)}(f)\) basada solamente en una parte de los datos (batch).
En cada iteración \(i\) sólo nos movemos en una dirección de descenso para los parámetros, sin intentar buscar un mínimo local o global. La dirección de descenso está dada por \(-\nabla L^{(i)}\).
Aunque este método es más útil en casos como redes neuronales o métodos basados en árboles, podemos comenzar por un ejemplo en regresión lineal para entender su efecto regularizador:
library(keras3)x_grasa <- grasa_receta |>prep() |>juice() |>select(abdomen, edad, antebrazo, biceps, estatura, muslo, pecho, peso) |>as.matrix()vars_nombres <-colnames(x_grasa)y_grasa <- grasa_receta |>prep() |>juice() |>pull(grasacorp)## keras tiene distintos algos de optimizaciónmodelo_reg <-keras_model_sequential() |>layer_dense(units =1, kernel_initializer =initializer_constant(0))modelo_reg |>compile(loss ="mse",optimizer =optimizer_sgd(learning_rate =0.01))# esto es más eficiente hacerlo con callbacks en general:pesos_tbl <-map_dfr(1:400, function(epoca){ modelo_reg |>fit(x = x_grasa, y = y_grasa,epochs =1, verbose =FALSE) pesos_tbl <-get_weights(modelo_reg)[[1]] |>t() |>as_tibble() names(pesos_tbl) <- vars_nombres pesos_tbl |>mutate(epoca = epoca) })
Y vemos que si inicializamos el proceso de minimización con valores chicos, pararnos en una época (iteración completa sobre los datos) nos permite tener un efecto similar al de utilizar regularización tipo L2.
Descenso estocástico
El método de descenso estocástico (usualmente por minilotes) nos permite resolver problemas de optimización, y muchas veces actúa también como regularizador (al cambiar en cada paso la función de pérdida, y utilizando early stopping). Sus ventajas son:
Al cambiar la función de pérdida en cada paso, es posible escapar de puntos estacionarios subóptimos (si el problema tiene varios puntos estacionarios, es decir, donde el gradiente es cero). Evitamos mínimos locales sobreajustados: estos desaparecen cuando consideramos “lotes” o “batches” de datos, en lugar del conjunto completo para cada iteración.
Generalmente detenemos las iteraciones cuando el error de validación deja de disminuir, lo cual es una forma de regularización que mantiene los parámetros en valores relativamente chicos.
Es eficiente en el sentido de que no es necesario utilizar todo los datos para hacer un paso suficientemente bueno, y es escalable a grandes conjuntos de datos.
Es crucial escoger un tamaño de paso adecuado para cada problema. Generalmente se considera un parámetro que debe ser afinado, de manera similar al parámetro de regularización L2 que vimos arriba.
Finalmente, notamos que este tipo de regularización resulta en comportamientos a veces inesperados del desempeño predictivo en función del tamaño del modelo utilizado, por ejemplo, puede ocurrir el fenómeno de doble descenso (ver James et al. (2014)):
Comenzando en modelos muy simples, al incrementar la complejidad o tamaño del model el error de prueba disminuye.
A partir de cierto momento, incrementar la complejidad incrementa el error de prueba (como esperaríamos por un aumento en varianza)
Sin embargo, si continuamos incrementando la complejidad, el error de prueba vuelve a descender, y llega a un valor más bajo que todos los observados anteriormente.
Esto se puede deber, por ejemplo, pues cuando existen pocos grados de libertad, la solución es escencialmente única (del paso 1 a 2 de arriba). Sin embargo, con modelos más grandes aparecen muchas otras soluciones posibles: las mejores en entrenamiento son peores en generalización, pero las que son “regularizadas” por descenso estocástico son mejores en desempeño predictivo. Puedes pensar en un polinomio de grado muy alto: la solución de grado alto que encontramos con descenso estocástico puede ser muy suave, en contraste con lo que encontraríamos si llegáramos a un mínimo global o cercano al global.
Chambers, J. M., W. S. Cleveland, B. Kleiner, y P. A. Tukey. 1983. Graphical Methods for Data Analysis. Chapman & Hall statistics series. Wadsworth International Group. https://books.google.com.mx/books?id=I-tQAAAAMAAJ.
Hastie, Trevor, Robert Tibshirani, y Jerome Friedman. 2017. The Elements of Statistical Learning. Springer Series en Statistics. Springer New York Inc. http://web.stanford.edu/~hastie/ElemStatLearn/.
James, Gareth, Daniela Witten, Trevor Hastie, y Robert Tibshirani. 2014. An Introduction to Statistical Learning: With Applications in R. Springer Publishing Company, Incorporated. http://www-bcf.usc.edu/~gareth/ISL/.